
Seven common mistakes that break your machine learning experiments’ credibility
Written by Andreas Maier
Machine learning is a great tool that is revolutionizing our world right now. There are lots of great applications in which machine and in particular deep learning has shown to be way superior to traditional methods. Beginning from Alex-Net for Image Classification to U-Net for Image Segmentation, we see great successes in computer vision and medical image processing. Still, I see machine learning methods fail every day. In many of these situations, people fell for one of the seven sins of machine learning.
While all of them are severe and lead to wrong conclusions, some are worse than others and even machine learning experts may commit such sins in their excitement on their own work. Many of these sins are hard to spot, even for other experts because you need to look at code and experimental setup in detail in order to be able to figure them out. In particular, if your results seem too good to be true, you may want to use this blog post as a checklist in order to avoid wrong conclusions about your work. Only if you are absolutely sure that you didn’t fall for any of these fallacies, you should go ahead and report your results to colleagues or the general public.
Sin #1: Data and Model Abuse
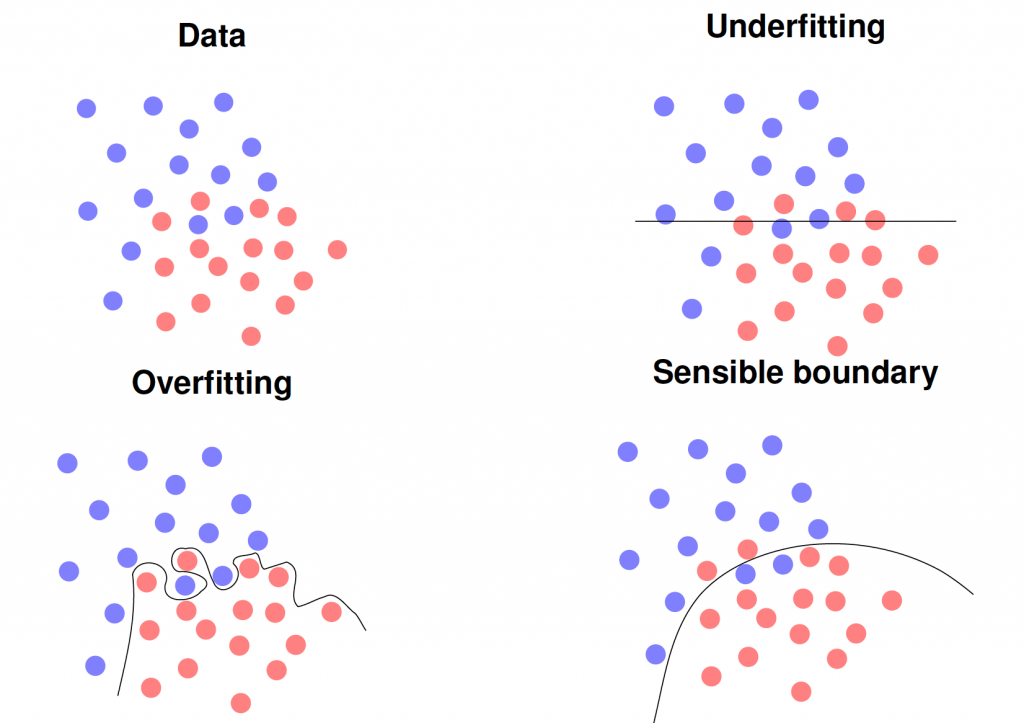
This sin is often committed by beginners in deep learning. In the most frequent occurrence, the experimental design is flawed, e.g. the training data is used as test data. With simple classifiers such as the nearest neighbor, this immediately leads to a 100% recognition rate for most problems. In more sophisticated and deep models, it may not be 100%, but 98-99% accuracy. Hence, you should always scrutinize your experimental setup if you achieve such high recognition rates in your first shot. If you go to new data, however, your model will completely break and you may even produce results that are worse than random guessing, i.e. lower accuracies than 1/K where K is the number of classes, e.g. less than 50% in a two-class problem. In the same line, you can also easily overfit your model by increasing the number of parameters such that it completely memorizes the training data set. Another variant is using a too-small training set that is not representative of your application. All these models are likely to break on new data, i.e. when employed in a real application scenario.
Sin #2: The Unfair Comparison

Even experts in machine learning may fall to this sin. It is typically committed if you want to demonstrate that your new method is better than the state-of-the-art. In particular research papers often succumb to this one, in order to convince reviewers of the superiority of their method. In the most simple case, you download a model from some public repository and use this model without fine-tuning or appropriate hyperparameter search to a model that was developed exactly to the problem at hand and you tweaked all parameters to get optimal performance on your test data. There are numerous instances of this sin in literature. The most recent example is exposed by Isensee et al. in their not-new-net paper in which they demonstrate that the original U-net outperforms virtually all suggested improvements of the method since 2015 on ten different problems. Hence, you should always perform the same amount of parameter tuning to the state-of-the-art model as you applied to your newly proposed method.
Sin #3: The Insignificant Improvement

After doing all the experiments, you finally found a model that produces better results than the state-of-the-art models. However, even at this point, you are not done yet. Everything in machine learning is inexact. Also, your experiments are influenced by many random factors due to the probabilistic nature of the learning process. In order take this randomness into consideration, you need to perform statistical testing. This is typically performed by running your experiments multiple times using different random seeds. This way, you can report an average performance and a standard deviation for all of your experiments. Using a significance test, like the t-test, you can now determine the probability that the observed improvements are merely related to chance. This probability should be at least lower than 5% or 1% in order to deem your results significant. In order to do so, you do not have to be an expert statistician. There are even online tools to compute them, e.g. for recognition rate comparison or correlation comparison. If you run repeated experiments, make sure that you also apply Bonferroni Correction, i.e. you divide the required significance level by the number of experimental repetitions on the same data. For more details on statistical testing, you should check this video of our Deep Learning Lecture.
Sin #4: Confounders and Bad Data
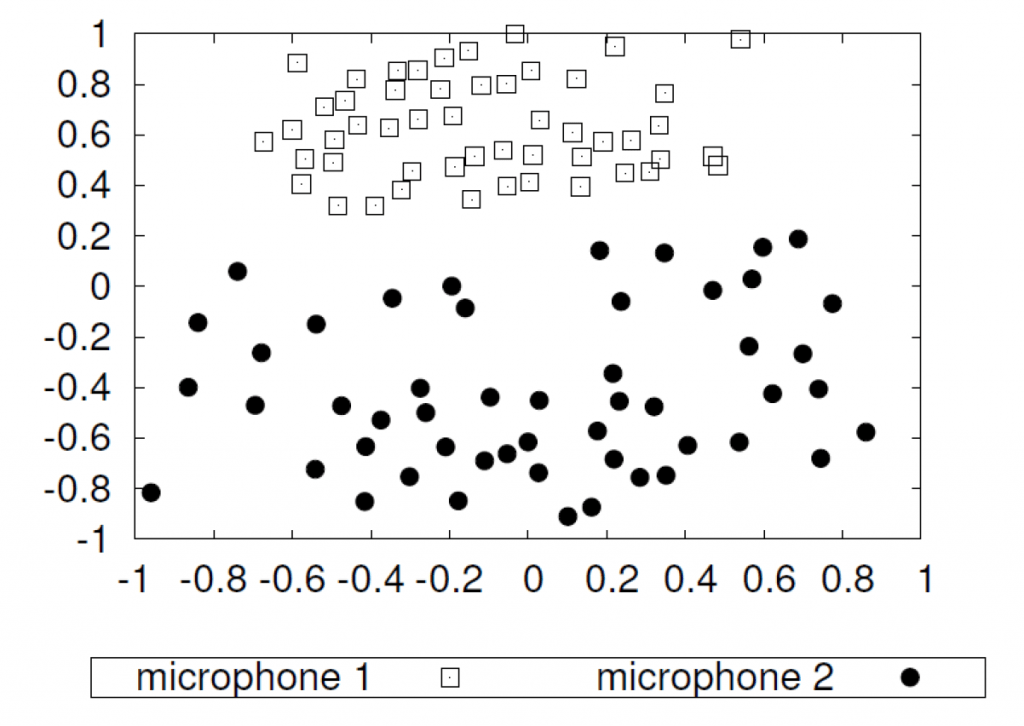
Data quality is one of the greatest pitfalls of machine learning. It may induce critical biases and even result in racist AI. The problem, however, does not lie in the training algorithm, but in the data itself. As an example, we show dimensionality reduced recordings of 51 speakers using two different microphones. Because, we recorded the same, speakers, they should actually be projected onto the same spot given appropriate feature extraction. However, we can observe that the identical recordings form two independent clusters. In fact, one microphone was located directly at the mouth of the speaker and the other microphone was located approximately 2.5 meters away on a video camera recording the scene. Similar effects can already be created by using two microphones from two different vendors or in the context of medical imaging by the use of two different scanners. If you now recorded all pathologic patients on Scanner A and all control subjects on Scanner B, your machine learning method will likely learn to differentiate the scanners instead of the actual pathology. You will be very pleased with the experimental results, yielding a close to perfect recognition rate. Your model, however, will completely fail in practice. Hence, please avoid confounders and bad data!
Sin #5: Inappropriate Labels
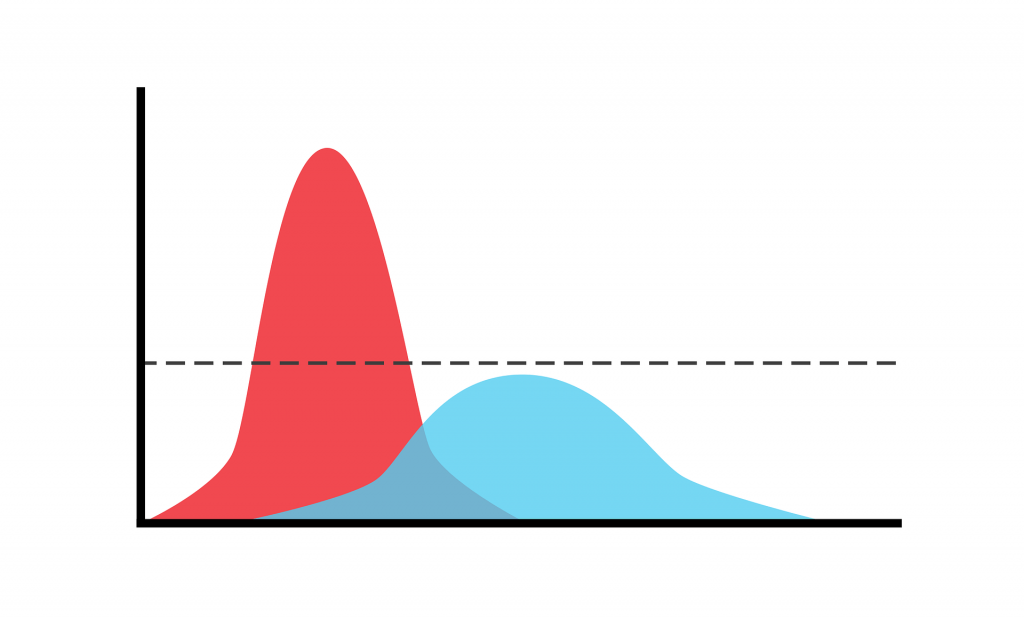
Already Protagoras knew: “Of all things the measure is man.” This also applies to the labels or ground truth of many classification problems. We train machine learning models to reflect man-made categories. In many problems, we think the classes are clear at the moment we define them. As soon as we look into the data, we see that it often also contains ambiguous cases, e.g. an image showing two objects instead of one in the ImageNet Challenge. It gets even more difficult if we go to complex phenomena such as emotion recognition. Here, we realize that in many real-life observations emotions can not be assessed clearly even by humans. In order to get correct labels, we need hence to ask multiple raters and obtain a label distribution. We depicted this in the above figure: The red curve shows a sharp-peaked distribution of a clear case, a so-called prototype. The blue curve shows a broad distribution of an ambiguous case. Here, not only the machine but also human raters are likely to end up in conflicting interpretations. If you used only one rater to create your ground truth, you will not even be aware of the problem which then gives typically rise to discussions on label noise and how to effectively deal with it. If you have access to the true label distributions (which is, of course, expensive to get), you can even demonstrate that you can dramatically increase your system’s performance by removing ambiguous cases, as we have seen for example in emotion recognition on acted emotions vs. real-life emotion. This, however, may not be the case in your real application as you have never seen an ambiguous case. Hence, you should prefer multiple raters over a single one.
Sin #6: Cross-validation Chaos
This is almost the same sin as Sin #1, but it comes in disguise and I have seen this even happen in almost submitted Ph.D. theses. So even experts can fall for this one. The typical setting is that you have a model, architecture, or feature selection in a first step. Because you have only a few data samples, you decided to use cross-validation to evaluate each step. So you split the data into N folds, select the features/model with N-1 folds, and evaluate on the N-th fold. After repeating this N-times, you compute the average performance and pick the features with the best performance. Now, that you know what the best features are, you go ahead and select the best parameters for your machine learning model using cross-validation.
This seems correct, right? No! It is flawed, because you already saw all the test data in the first step and averaged all observations. As such the information from all the data is conveyed to the next step, and you can even get excellent results from completely random data. In order to avoid this, you need to follow a nested procedure which nests the first step inside the second cross-validation loop. Of course, this is very costly and produces a lot of experimental runs. Note that only due to the large number of experiments that you are conducting on the same data, in this case, you are also likely to produce a good result only due to chance. As such statistical testing and Bonferroni Correction are again mandatory (cf. Sin #3). I would generally try to avoid large cross-validation experiments and try to get more data such that you can work with a train/validation/test split.
Sin #7: Overinterpretation of Results

Aside from all the previous sins, I think the greatest sin that we are often conducting in machine learning, right now in the current hype phase, is that we overinterpret and overstate our own results. Of course, everybody is happy with the successful solutions created with machine learning and you have all the right to be proud of them. However, you should avoid extrapolating your results on unseen data or state to have solved a problem generally, because you have tackled two different problems with the same method.
Also, claims of super-human performance raise doubts because of the observations we made in Sin #5. How would you outperform the source of your labels? Of course, you can beat one human with respect to fatigue and concentration, but outperform humanity in general on man-made classes? You want to be careful with this claim.
Every claim should be based on facts. You can hypothesize on the universal applicability of your method in discussions clearly indicating the speculation, but to actually claim this you have to provide either experimental or theoretical evidence. Right now, it is hard to get your method the visibility that you think that it deserves and stating big claims will of course help to popularize your method. Still, I recommend to stay on the ground and to stick to the evidence. Otherwise, we might very quickly end up with the next AI Winter and the general suspicion of artificial intelligence that we already had in previous years. Let’s avoid this in the current cycle and stick to what we are really able to demonstrate to achieve.
Of course, most of you already knew these pitfalls. However, you may want to have a look at the seven sins of machine learning every now and then, just to make sure that you are still on the ground and have not fallen for them:
Sin #1: Data and Model Abuse – Split training and test, check for overfitting!
Sin #2: The Unfair Comparison – Also tune the baseline model!
Sin #3: The Insignificant Improvement – Do significance testing!
Sin #4: Confounders and Bad Data – Check your data & acquisitions!
Sin #5: Inappropriate Labels – Use multiple raters!
Sin #6: Cross-validation Chaos – Avoid too much cross-validation!
Sin #7: Overinterpretation of Results – Stick to the evidence!
If you liked this essay, you can find more essays here, more educational material on Machine Learning here, or have a look at my Deep Learning Lecture. I would also appreciate a clap or a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.