
Written by Prathmesh Madhu
Contribution
This work exploits style transfer in combination with transfer learning to recognize characters in art historical images. Our approach focuses on recognizing two central characters in the “Annunciation of the Lord” scene from Art history, Mary and Gabriel across varied art-works from different artists, times and styles. This is different compared to the existing methods in art history, where the models are trained on artworks relating to either a specific style or an artist.
Outcomes
- understanding the semantics to recognize characters in art historical images irrespective of styles and times.
- proof of concept for enhancing recognition models using style-transfer; information from styled images is beneficial for improving the performance of the deep CNN models.
- Validating the claim that our method captures more contextual and semantic information by visualizing the class-activation maps; also to better understand the model performances and for further enhancements.
- Performance of traditional machine learning models (SVMs, Decision Trees) decrease when they are trained on the whole body of the characters as opposed to only faces
Limitations
- It’s not an end-to-end pipeline.
- The current algorithm is only trained for 2 characters – Mary and Gabriel. We are already working on increasing the number of characters.
- Since, there is no existing method for art history for comparison, there is no comparison with any SOTA methods.
Overview of the Methodology
Authors: Prathmesh Madhu, Ronak Kosti, Lara Mührenberg, Peter Bell, Andreas Maier, Vincent Christlein
Preprint: https://arxiv.org/pdf/2003.14171.pdf
ACM Published Link : https://dl.acm.org/doi/10.1145/3347317.3357242
Code: https://github.com/prathmeshrmadhu/recognize_characters_art_history
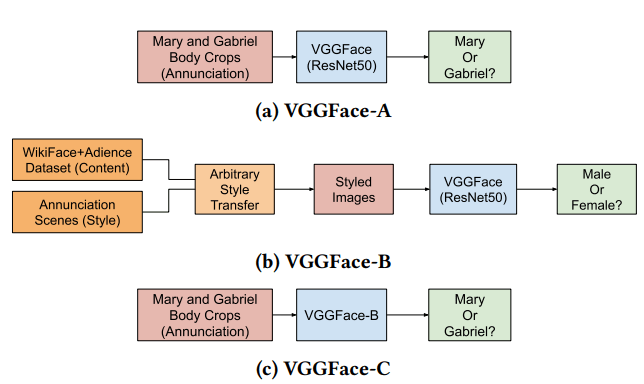
We train VGGFace model on Mary and Gabriel body crops which is called VGGFace-A (baseline). We then train another VGGFace on Styled Dataset and call it VGGFace-B. We then finetune VGGFace-B by Mary and Gabriel body crops and call it VGGFace-C which is the Styled transfer learned model.
Generating Styled Dataset

Content Images : We chose to use IMDB-Wiki [1] and Adience [2] since the images are not only limited to faces, but also contain the upper body part. Combining both, we have around 20000 images belonging to each class, male and female, which we call the content images
Style Images : Our annunciation dataset (from which Mary and Gabriel body crops are generated) has 2787 images which we call the style images.
Using a style transfer model, based on adaptive instance normalization, introduced by Huang and Belongie [3], we transferred the artistic style of style images to the content images.
Results
- Quantitatively, we recieved an average 7% rise in accuracy compared to baseline and 8% compared to traditional approaches.
- Qualitatively, we can observe in the CAMs that our model very well learns the semantics and context from the styled informed models.

Row 1 shows the original images. Row 2 are the CAMs for VGGFace-A and Row 3 are the CAMs for VGGFace-C (styled transfer learned) model. Once can observe in the (c) column how the context of the dress is adapted, while how model focused itself more on the facial region in Column (d).
References:
[1] Eran Eidinger, Roee Enbar, and Tal Hassner. 2014. Age and gender estimation of unfiltered faces. IEEE Transactions on Information Forensics and Security 9, 12 (2014), 2170–2179.
[2] Rasmus Rothe, Radu Timofte, and Luc Van Gool. 2016. Deep expectation of real and apparent age from a single image without facial landmarks. International Journal of Computer Vision (IJCV) (July 2016).
[3] Xun Huang and Serge Belongie. 2017. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision. 1501–1510