NewsUnderstanding Compositional Structures in Art Historical Images using Pose and Gaze Priors
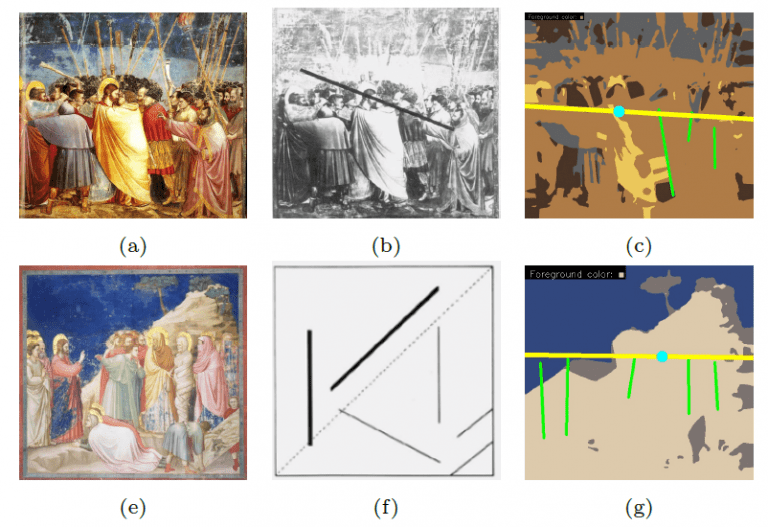
Written by Prathmesh Madhu Contribution Inspired from the pioneer work of Max Imdahl [1], our work focuses on generating image composition canvas (ICC) diagrams based on two central themes: (a) detection of action regions and action lines of an artwork (b) pose-based segmentation of foreground and background. In order to validate our approach qualitatively and quantitatively, we conduct a […]Written by Prathmesh Madhu Contribution Inspired from the pioneer work of Max Imdahl [1], our work focuses on generating image composition canvas (ICC) diagrams based on two central themes: (a) detection of action regions and action lines of an artwork (b) pose-based segmentation of foreground and background. In order to validate our approach qualitatively and quantitatively, we conduct a […]