Multi-modal (Audio, Text, Visual) Emotion Recognition
Grant Awardee: Ronak Kosti
Grant Duration: July-2020 to June-2021
Project Description
We recognize people’s emotions from their facial expressions, body posture, behavior and social interaction with other people. It is an essential ability which helps to understand what people are feeling in general, but also to respond appropriately. For example, if a person is sad and feeling unhappy, instinctively we are ready to offer our support and empathize with him. While looking at an image or a video, particular attributes of the image/video evoke emotional response in the observer. Recognizing such attributes or image/video features will help us understand underlying character of emotions in images and videos.
Contextual information like the scene surrounding the person also enhances our perception of other people’s emotion. An emotion recognition system which uses the information present in
the surrounding scene, in addition to the body posture, has been successfully implemented in previous work [1]. In this system, the features extracted from the body posture of a person as well as the whole image are encoded by the system in a common feature space that encodes the emotion of the person. However, the relationship between the location in the scene that evoked a particular emotion and it’s corresponding audio speech has not been explored yet. In order to circumvent the limitations of current recommendation systems, the idea is to integrate audio speech in combination with labeled images to improve the user-experience and state-of-the art methods.
Aims:
- Bridge the gap of simultaneous visual and audio recognition of emotions.
- Aligning the lexical content of audio speech signals (which describe the emotional content of the image) with their corresponding location in the image.
- Localizing the emotional region of interest in images and videos.
- Learning a common multi-modal emotion-embedding space for the visual and audio features that correspond to a given emotion. Specifically learning an audio unit that corresponds to specific emotions.
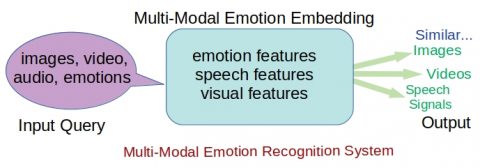
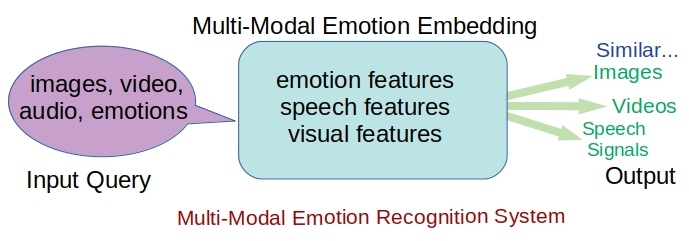
- Build an emotional retrieval system (featured image), that takes images or video or audio speech and retrieves similar related content.
Methodology
Current state of the art system [2] is able to localize the region in an image whose description is given by the corresponding speech audio signal. The system jointly encodes speech and image features in the modeling. Such systems have learned the lexical content of the audio speech signal, and associate them to the corresponding spatial regions. This pioneering work has created the possibility to use the audio speech as a guidance signal. The proposal (featured image) is to create a common embedding space for image, video and speech audio signals. The system is modeled using a multi-modal and multi-task framework. Emotion recognition using multi-modal framework (audio speech, image, video and emotion labels) will help in understanding of the influence of the context. This methodology will be applied to localize emotional content in the images.
EMOTIC dataset [1] serves as starting point. It has 34320 people (23571 images) with their corresponding emotion labels. In brief, the intention is to accomplish the following:
- Augmenting EMOTIC dataset [1] with audio speech signals.
- Each of the 34320 people in EMOTIC will be associated with their corresponding audio speech signals which will be able to describe the emotional content of the scene
- Using multi-task framework, integrate the newly generated audio speech signals into a common embedding space.
- A multi-modal system that encodes audio speech signals and it’s corresponding image features will be developed that uses the common embedding of image and audio features.
- Developing this system will give us insights into discovering ‘audio units’ corresponding to the different emotional aspects of the images. At the end, we will have a system that can improve our understanding of audio speech (based on emotions) and visual features.
References:
[1] Ronak Kosti, Jose M. Alvarez, Adria Recasens, and Agata Lapedriza. “Emotion recognition in context.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1667-1675. 2017. Link to the paper
[2] David Harwath, Adrià Recasens, Dídac Surís, Galen Chuang, Antonio Torralba, and James Glass. “Jointly discovering visual objects and spoken words from raw sensory input.” In Proceedings of the European Conference on Computer Vision (ECCV), pp. 649-665. 2018. Link to the paper