
Multi-task Learning
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning“. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!

Welcome everybody to deep learning! So today, we want to conclude talking about different regularization methods. We want to talk in particular about one more technique that is called multitask learning. In multi-task learning, we want to extend the previous concepts. Previously, we only had one network for one task. Then, we had transfer learning to reuse the network. The question is can we do more? Can we do it in a better way? There are some real-world examples. For example, if you learn to play the piano and the violin, then in both tasks, you require a good hearing, a sense of rhythm music notation, and so on. So, there are some things that can be shared. Also, soccer and basketball training both require stamina, speed, body awareness, and body-eye coordination. So, if you learn the one then you typically also have benefits for the other. So, this would be even better than reusing as you learn simultaneously and then provide a better understanding of the shared underlying concepts.

The idea now is that we train our network simultaneously on multiple related tasks. So, we adapt the loss function to assess performance for multiple tasks and this then results in multi-task learning that introduces a so-called inductive bias. As a result, we prefer a model that can explain more than a single task. Also, this reduces the risk of overfitting on one particular task and our model generalizes better.
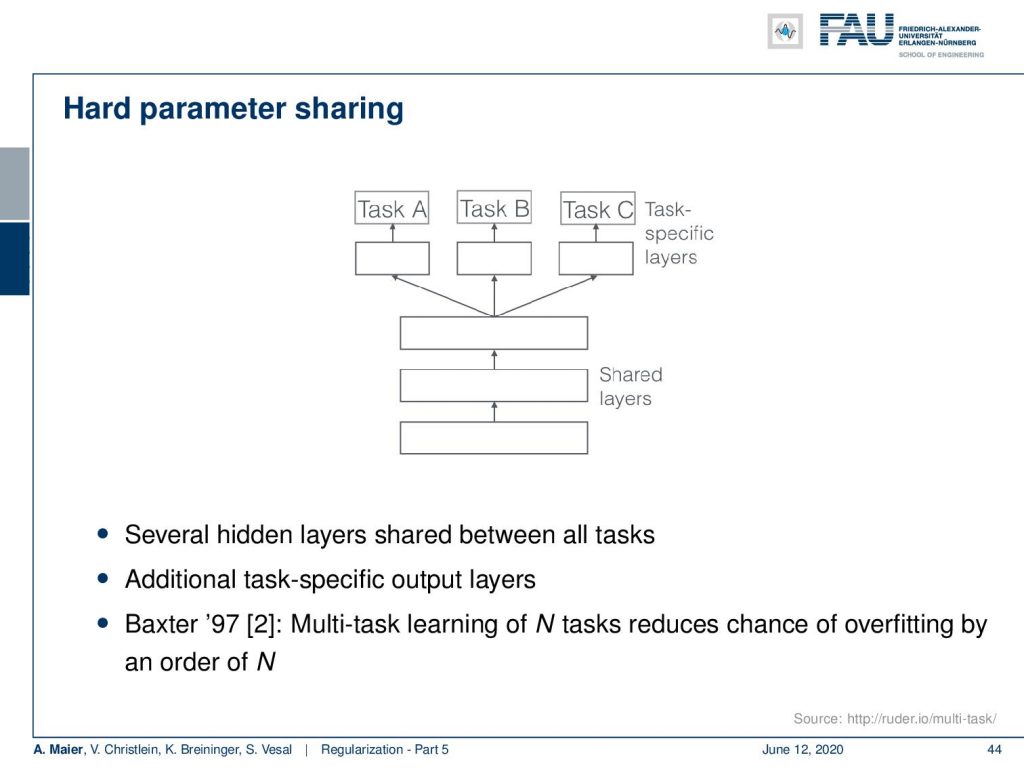
So, let’s look at the setup. So, we have some shared input layers and these are like the feature extraction layers or representation layers. Then, we split at some point where we go into task-specific layers to evaluate on Task A, Task B, and Task C. They may be very different but somehow related because otherwise, it wouldn’t make sense to share the previous layers. So several hidden layers are shared between all of the tasks. As already shown by Baxter in [2], multi-task learning of N tasks reduces the chance of overfitting by an order of N.
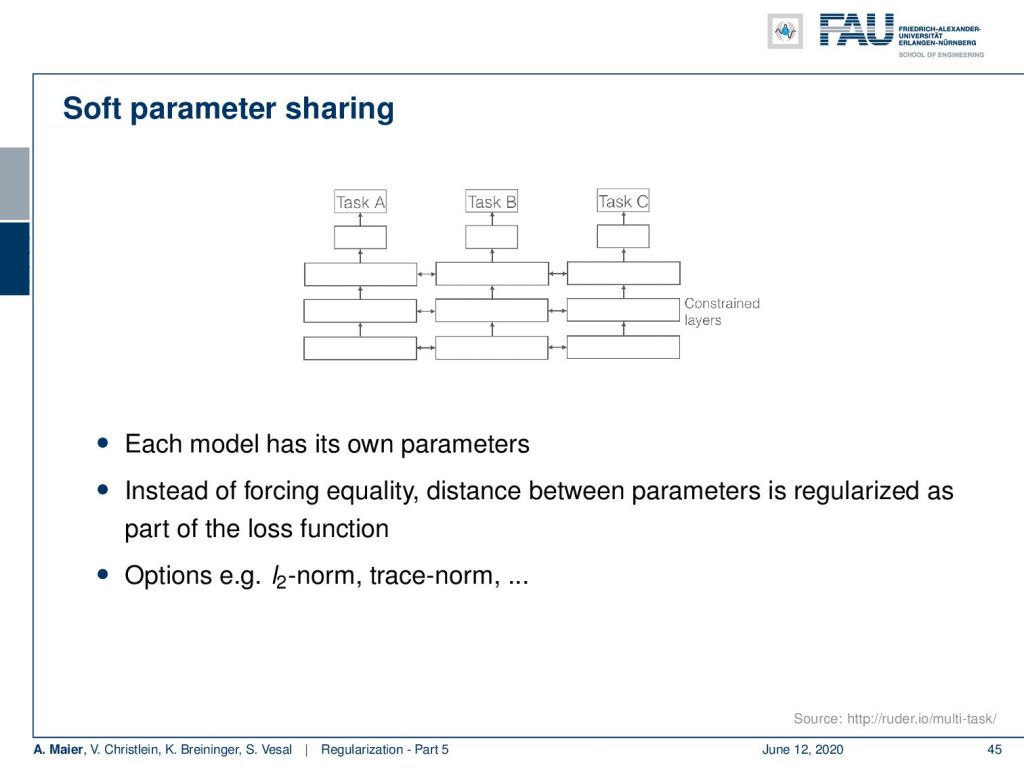
Instead of hard sharing, you can also do soft parameter sharing. It introduces an additional loss. So, you constrain the activations in the respective layers to be similar. Hence, each model has its own parameters, but we link them together to perform similar, yet different extraction steps in the constrained layers. You can do that for example with an L2 norm or other norms that make them similar.

Now, we still have to talk about auxiliary tasks. All of these tasks should have their own purpose. You may also just include auxiliary tasks just because you want to create a more stable network. So, one example here is facial landmark detection by Zhang et al. [22]. They essentially want to detect facial landmarks, but this is impeded by occlusion and post variances. So, they start simultaneously to learn landmarks and subtly related tasks, like the face pose, smiling vs. not smiling, glasses vs. no glasses, and gender. They had this information available and then you can set this up in a multitask learning framework as you see here in the network architecture.

In the results, you see how the auxiliary tasks support the detection of the facial landmarks. They compare this to a CNN, a cascaded CNN, and their multitask network with the auxiliary tasks. The landmark detection is improved by the introduction of these auxiliary tasks. So, certain features may be difficult to learn for one task, but it may be easier for a related one. The auxiliary task can help to steer the training in a specific direction and we somehow include prior knowledge by choosing appropriate auxiliary tasks. Of course, tasks can have different convergence rates. To alleviate the problem, you can then also introduce task-based early stopping. An open research question is what tasks are appropriate auxiliary tasks. So this is something, we cannot generally answer, but is typically determined by experimental validation.

So next time on deep learning, we start with a new topic where we look into some practical recommendations to actually make things work. So with all you’ve seen you’re already, we are pretty far, but there’s a couple of hints that will make your life easier. So, I definitely recommend watching the next couple of lectures. We will look into how to evaluate performance and deal with the most common problems that essentially everybody has to face in the beginning. Also, we look at concrete case studies with all the pieces that you learned until now.

I have a couple of comprehensive questions like: “What is the bias-variance trade-off?” “What is model capacity?” “Describe three techniques to address overfitting.” “What connects the covariate shift problem and the ReLU?” “How can we address the covariate shift problem?”, and so on. Further reading, you can find on the links which I posted below this text. Thank you very much for reading and see you in the next lecture!
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
Links
Link – for details on Maximum A Posteriori estimation and the bias-variance decomposition
Link – for a comprehensive text about practical recommendations for regularization
Link – the paper about calibrating the variances
References
[1] Sergey Ioffe and Christian Szegedy. “Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift”. In: Proceedings of The 32nd International Conference on Machine Learning. 2015, pp. 448–456.
[2] Jonathan Baxter. “A Bayesian/Information Theoretic Model of Learning to Learn via Multiple Task Sampling”. In: Machine Learning 28.1 (July 1997), pp. 7–39.
[3] Christopher M. Bishop. Pattern Recognition and Machine Learning (Information Science and Statistics). Secaucus, NJ, USA: Springer-Verlag New York, Inc., 2006.
[4] Richard Caruana. “Multitask Learning: A Knowledge-Based Source of Inductive Bias”. In: Proceedings of the Tenth International Conference on Machine Learning. Morgan Kaufmann, 1993, pp. 41–48.
[5] Andre Esteva, Brett Kuprel, Roberto A Novoa, et al. “Dermatologist-level classification of skin cancer with deep neural networks”. In: Nature 542.7639 (2017), pp. 115–118.
[6] C. Ding, C. Xu, and D. Tao. “Multi-Task Pose-Invariant Face Recognition”. In: IEEE Transactions on Image Processing 24.3 (Mar. 2015), pp. 980–993.
[7] Li Wan, Matthew Zeiler, Sixin Zhang, et al. “Regularization of neural networks using drop connect”. In: Proceedings of the 30th International Conference on Machine Learning (ICML-2013), pp. 1058–1066.
[8] Nitish Srivastava, Geoffrey E Hinton, Alex Krizhevsky, et al. “Dropout: a simple way to prevent neural networks from overfitting.” In: Journal of Machine Learning Research 15.1 (2014), pp. 1929–1958.
[9] R. O. Duda, P. E. Hart, and D. G. Stork. Pattern Classification. John Wiley and Sons, inc., 2000.
[10] Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. http://www.deeplearningbook.org. MIT Press, 2016.
[11] Yuxin Wu and Kaiming He. “Group normalization”. In: arXiv preprint arXiv:1803.08494 (2018).
[12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, et al. “Delving deep into rectifiers: Surpassing human-level performance on imagenet classification”. In: Proceedings of the IEEE international conference on computer vision. 2015, pp. 1026–1034.
[13] D Ulyanov, A Vedaldi, and VS Lempitsky. Instance normalization: the missing ingredient for fast stylization. CoRR abs/1607.0 [14] Günter Klambauer, Thomas Unterthiner, Andreas Mayr, et al. “Self-Normalizing Neural Networks”. In: Advances in Neural Information Processing Systems (NIPS). Vol. abs/1706.02515. 2017. arXiv: 1706.02515.
[15] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. “Layer normalization”. In: arXiv preprint arXiv:1607.06450 (2016).
[16] Nima Tajbakhsh, Jae Y Shin, Suryakanth R Gurudu, et al. “Convolutional neural networks for medical image analysis: Full training or fine tuning?” In: IEEE transactions on medical imaging 35.5 (2016), pp. 1299–1312.
[17] Yoshua Bengio. “Practical recommendations for gradient-based training of deep architectures”. In: Neural networks: Tricks of the trade. Springer, 2012, pp. 437–478.
[18] Chiyuan Zhang, Samy Bengio, Moritz Hardt, et al. “Understanding deep learning requires rethinking generalization”. In: arXiv preprint arXiv:1611.03530 (2016).
[19] Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, et al. “How Does Batch Normalization Help Optimization?” In: arXiv e-prints, arXiv:1805.11604 (May 2018), arXiv:1805.11604. arXiv: 1805.11604 [stat.ML].
[20] Tim Salimans and Diederik P Kingma. “Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks”. In: Advances in Neural Information Processing Systems 29. Curran Associates, Inc., 2016, pp. 901–909.
[21] Xavier Glorot and Yoshua Bengio. “Understanding the difficulty of training deep feedforward neural networks”. In: Proceedings of the Thirteenth International Conference on Artificial Intelligence 2010, pp. 249–256.
[22] Zhanpeng Zhang, Ping Luo, Chen Change Loy, et al. “Facial Landmark Detection by Deep Multi-task Learning”. In: Computer Vision – ECCV 2014: 13th European Conference, Zurich, Switzerland, Cham: Springer International Publishing, 2014, pp. 94–108.