
Every model is wrong, but some models are useful
Written by Andreas Maier.
We have seen tremendous progress by artificial intelligence (AI) over the past decades. This progress, however, was not achieved steadily. There were significant ups and downs on the way. In some of these phases, people were even afraid to openly commit to the term artificial intelligence, as the reputation of the field was severely damaged. Anybody working on AI was considered a dreamer at that time. This also led to different names and subdivisions of the field being called machine learning, data mining, or pattern recognition.
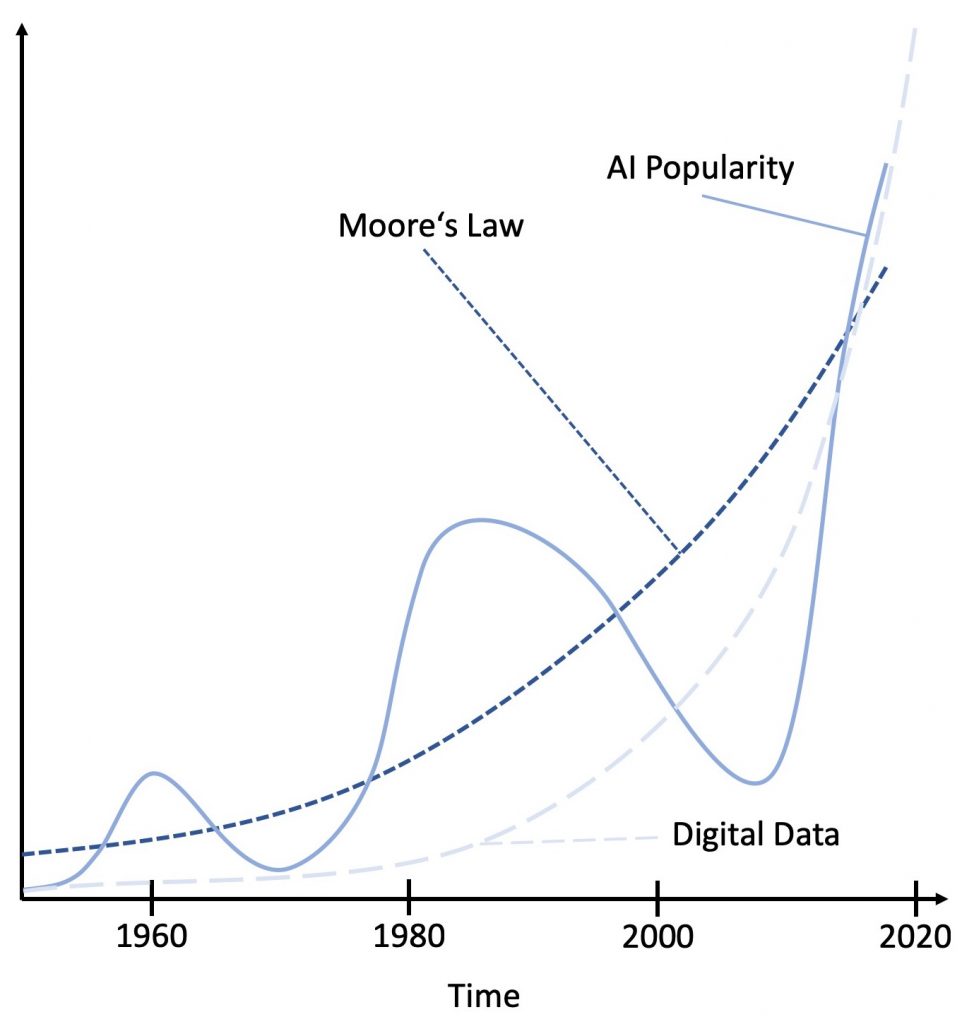
In a recent blog post by Richard Sutton, the lack of computational power was identified as a significant reason for the ups and downs that have been encountered so far. In his thorough analysis, the observation is made that general models have always outperformed models that were mainly driven by expert knowledge. With increasing compute-power, the general models were able to outperform the hand-crafted, expert knowledge-based models. However, at the point when general models became computationally too expensive, Moore’s Law struck and further progress using general approaches became impossible. Figure 1 demonstrates this development schematically. Based on this analysis, the conclusion is drawn that the incorporation of expert knowledge is a waste of resources, as one only needs to wait until enough compute-power is available to solve the next milestone in machine intelligence. This conclusion is quite radical and deserves a little more analysis. Hence, we will have a short historical perspective, that is, in fact, a short summary of three articles that have been published recently on KDnuggets.
The first AI Hype started in the 1950s and led to important developments in the field. Minsky developed the first neural network machine called Stochastic Neural Analogy Reinforcement Computer (SNARC), which was inspired by biological design and mapped neurons into an electrical machine. Further important developments were the Perceptron that made biologically inspired neurons trainable in a computer program. Another important development of that era was the invention of rule-based grammar models that were employed to solve the first simple natural language processing tasks. Also, the concept of the Turing Test falls into this period of AI. With these great developments, high expectations for AI were gradually growing faster and faster. Yet, these concepts could not live up to their expectations and fail in many daily life applications. These doubts were further supported by theoretical observations, e.g. that the Perceptron is not able to learn the logical XOR function, as it is not linearly separable. As a result, funding in AI was tremendously cut which is also known as the AI Winter today.
In the 80’s the fascination of AI returned. This second boom was fostered by the development of more important techniques such as the back-propagation algorithm that made Multi-Layer Perceptrons trainable and the theoretic observation that a neural network with a single hidden layer is already a general function approximator. Recurrent nets were developed and reinforcement learning made game theory also trainable. Another breakthrough of that time was the development of statistical language models that gradually started to replace rule-based systems. Even deep and convolutional networks were already explored at that time. Yet, the ever-growing computational demand – supported by numerical instabilities – resulted in long training times. At the same time, other model-based, less complex techniques such as Support Vector Machines and Ensembling emerged that gradually reduced the importance of neural networks as the same or better results could be obtained in less time. In particular convex optimization and variational methods became important concepts effectively putting an end to this second AI hype. At that time, neural networks were known to be inefficient and numerically unstable. Many researchers would no longer invest their time in this direction as other methods were more efficient and could process data more efficiently.
The third hype period, the one that we are currently experiencing is again driven by many important breakthroughs. We have seen computers beat world-class Go players, creating art, and solving previously close-to-impossible-appearing tasks such as image captioning. A major reoccurring theme in this present period is that hand-crafting and feature-engineering are no longer required and deep learning algorithms solve everything out-of-the-box. In fact, important concepts have been discovered that we’re able to generalize on many state-of-the-art approaches. Deep convolutional networks have replaced multi-scale approaches like SIFT and Wavelet theory. Also, trainable convolutional neural networks have demonstrated to outperform so-called Mel Frequency Cepstrum Coefficients (MFCCs) in speech processing where these features have dominated the field for almost 50 years. It seems that much of the theory that has been developed in the past has become obsolete. Yet, one has to keep in mind that deep network design is in fact often inspired by the classical feature extraction models and that image processing features share distinct similarities with Wavelet transforms and audio processing networks still form implicit filter banks. As such the knowledge is still there, but it is encoded in a different form. Still one has to acknowledge that the trainable versions of previous algorithms clearly outperform their predecessors.
Our current analysis lacks a third component that is another driver of today’s success in AI: The availability of digital data for training the machine learning algorithms (cf. Figure 1). In a recent article, Helbing and colleagues observe that data doubles every 12 months, while even GPU processing power only doubles in 18 months. As a result, we will soon no longer be able to process data as exhaustive as we do today. We either have the option to process only a limited amount of data or we have to limit the complexity of the approaches that we use to process them. As a result, model-based approaches might soon take over again and we may experience another period in which non-general and specialized models will drive research.
This kind of research seems in vain as it may be replaced at some point by more general models. Yet, we have to keep in mind another significant advantage of models: They can be understood and manipulated accordingly. Take a physical formula, for example, that can be solved for one variable or another. We can perform this with all models and use their properties to rearrange them towards new uses. This is something that we cannot do with present deep learning models. They have to be trained from scratch and their ability to be reused is only limited. As such models also have a lot to offer that current deep learning is not able to do.
For the far future, we can already speculate that such knowledge-driven AI will be replaced in years to come by true general AI that is able to create, maintain, and reuse such models on its own as Sutton predicts. In the opinion of the author of this article, however, approaches to combine domain-knowledge with deep learning are not in vain, as the next level of generalization will be achieved by lessons learned from model-driven AI that is still to come. While developing model-driven AI, we will understand how to build good trainable model-AI solutions and finally create automated methods to achieve the same.
Of course, it is difficult to make predictions, especially about the future. Either way, be it general model-free approaches or model-driven science, we are looking at exciting years to come for machine learning, pattern recognition, and data mining!
If you liked this blog post, we recommend reading our other posts on MarkTechPost.com or having a look at our free deep learning resources.
Text and images of this article are licensed under Creative Commons License 4.0 Attribution. Feel free to reuse and share any part of this work.