Lecture Notes in Pattern Recognition: Episode 1 – Introduction

These are the lecture notes for FAU’s YouTube Lecture “Pattern Recognition“. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. Try it yourself! If you spot mistakes, please let us know!
Welcome, everybody! My name is Andreas Maier and I am teaching this semester Pattern Recognition at Friedrich-Alexander-University Erlangen Nuremberg. So we are teaching this class as an advanced class for machine learning. We will focus on the classical methods of machine learning. It will involve quite a bit of math and we aim to link math, statistics, and probability theory together with machine learning and we will talk about linear methods up to kernel methods that will involve high-dimensional spaces. So I think the background that you get in this class is crucial for understanding, of course, classical machine learning, but also methods of deep learning. All that you see here is being published under a Creative Commons 4.0 license (CC BY 4.0), so you are welcome to reuse any of the material that we present here. We will also publish all of these videos on our own system, which is called fau.tv, and as well on YouTube. I will post also the links in the description of this video. So this would be the right point to subscribe to those videos because then you will see all of the videos that we will publish throughout the entire semester. So with that being said, I think we are going ahead to some exciting lectures over the next semester. I‘m looking forward to demonstrating Pattern Recognition to you.

We want to start today by talking about the introduction. So, Pattern Recognition in Erlangen has actually quite some history. The Pattern Recognition Lab has been founded by Professor Niemann you can see here on the left-hand side. The lab was then later continued by Professor Hornegger, who is now the president of the university. You can see that quite a bit of what we are demonstrating here in this class goes way back to the roots of the class that Professor Niemann was already teaching. Then there was a major rehaul of the entire lecture that was done by Professor Hornegger. The slides as you can see here in this final presentation form have been created by Stefan Steidl. So he did a lot of the contributions that you see here. A lot of the different figures and animations that you will see in the next couple of slides have been created by him. Dr. Steidl unfortunately passed in 2018. Stefan Steidl has been an amazing scholar, a dedicated researcher, and a very good friend. So I am very happy that I can share the slides created by him with you today in this video as well as for the entire lecture.
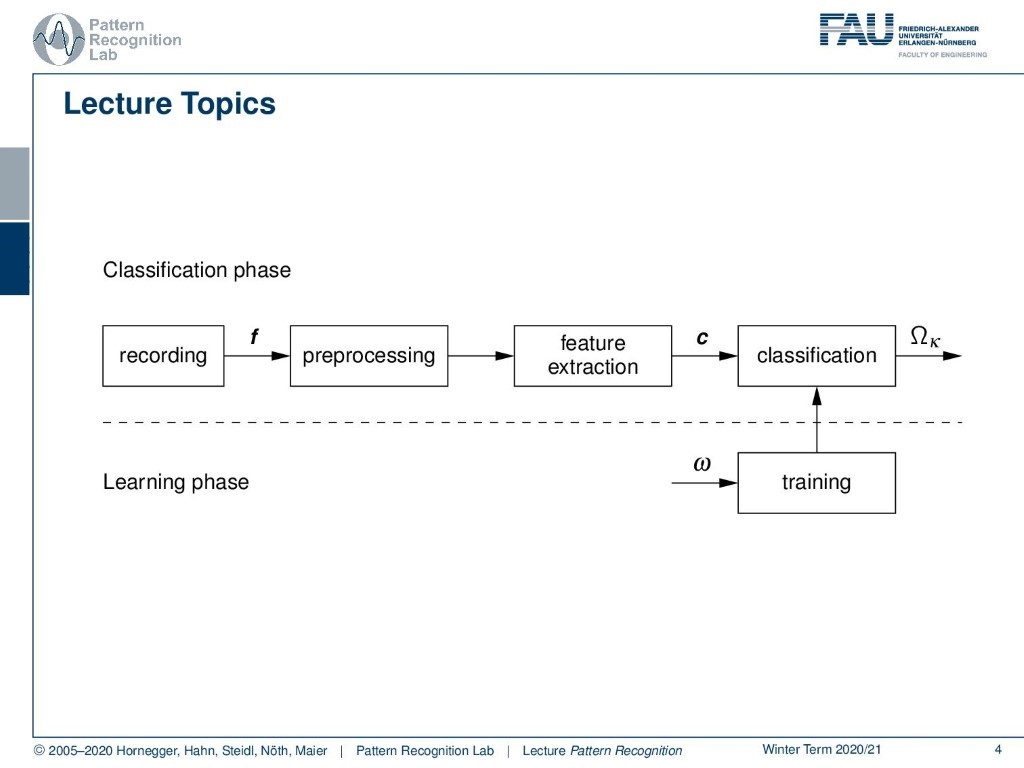
So let’s talk a bit about the topic of Pattern Recognition! This is the classical pattern recognition pipeline. So you see that we start typically by recording some signal, it could be an image or a speech signal, that is then pre-processed. This means that the signal is essentially preserved in its original shape so it can be played back if it’s an audio signal after the pre-processing. If it’s an image signal you can still look at the image after pre-processing. After that, we perform feature extraction and the feature extraction is used to create meaningful numbers out of the signals. These signals are then used in the classification stage such that they can be assigned to an abstract class Ω subscript κ.
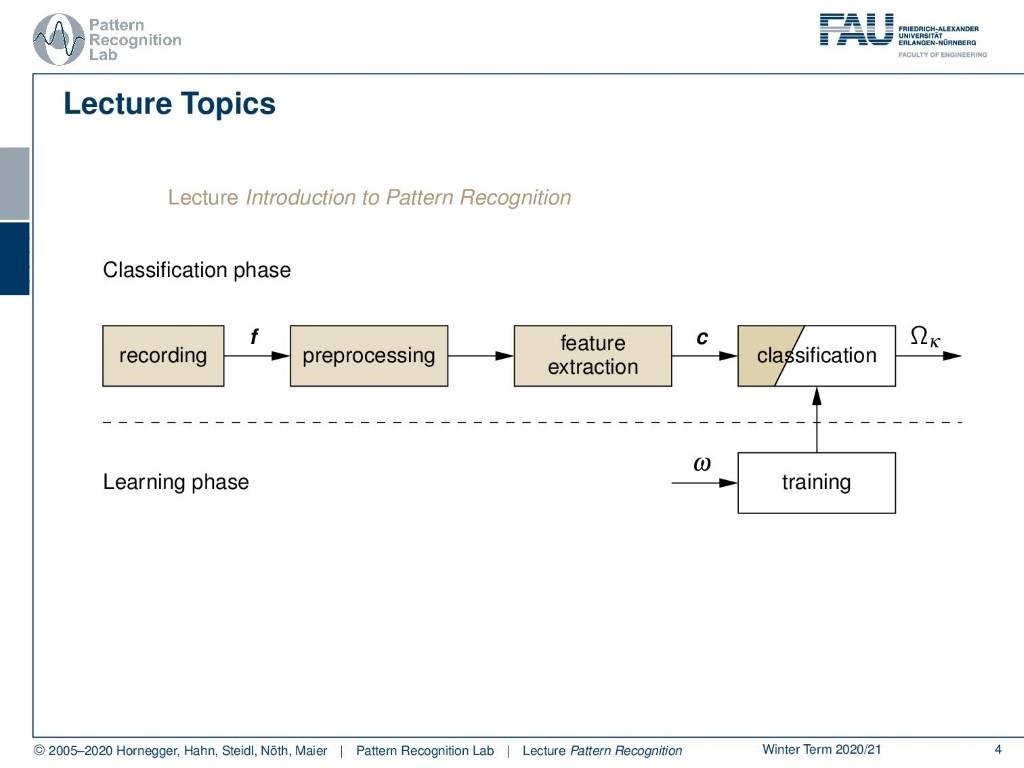
This entire pattern recognition system we essentially split up into two lectures. The first one is Introduction to Pattern Recognition. So here we talk about the entire feature extraction, typical image and speech processing features, as well as some simple classifiers such that you can build your own classification systems.
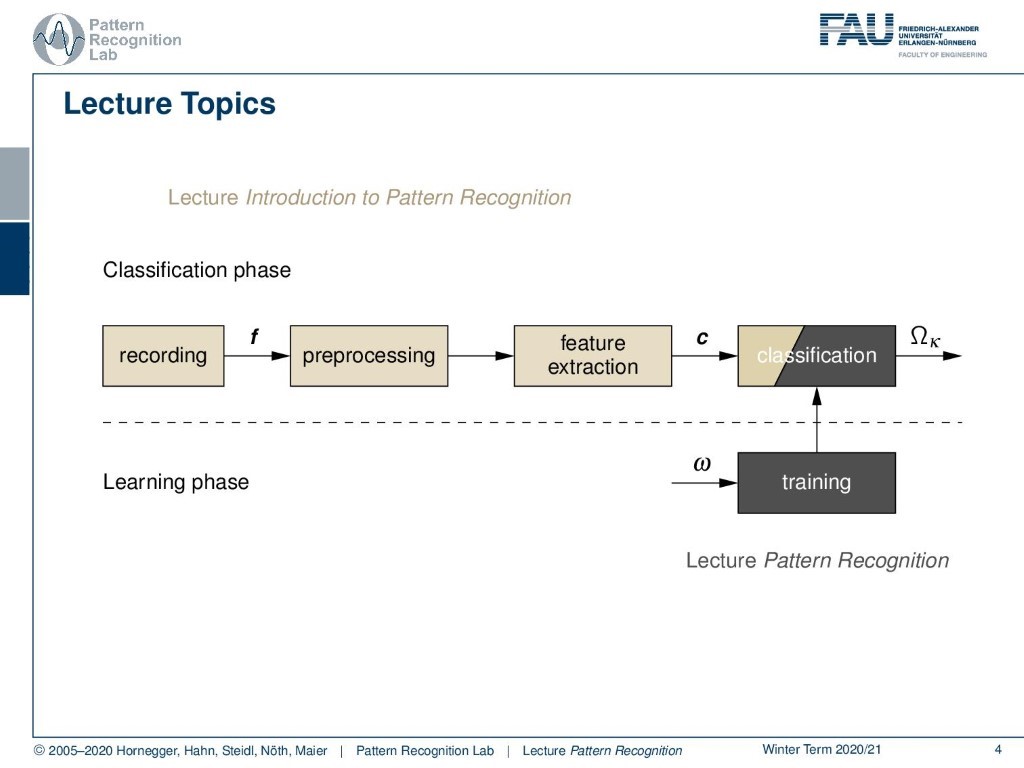
The class that you’re listening to today is looking into classification and the training part here in-depth. And we will talk about many of the advanced methods in machine learning.

So you can see here our lecture topics. We start with general theory about the Bayes theorem and probabilistic theory, then we go ahead and talk about the naive Bayes classifier. We will also talk about logistic regression and this will be followed by discriminant analysis as well as perceptrons. We will talk also a bit about multi-layer perceptrons and neural networks. Then we will talk about support vector machines, and of course, all of the time the points of norms and optimization will be very important for us as our kernel methods. In the end, we will look into the expectation-maximization algorithm as well as boosting and we will talk about other boosts.

So you could say: „What is Pattern Recognition good for“? Well, I already hinted that you can do of course speech recognition, you can do image processing and image recognition to classification. We will see that fingerprint identification is a typical such problem, but also optical character recognition falls into the class of pattern recognition algorithms. These things are of course important in industrial workflows for quality control, for sorting. You see today all kinds of machines from barcode readers to machines that sort your bins when you return them to the supermarket. All of them employ pattern recognition techniques, and you will learn the essential methods to actually build algorithms that are able to solve these tasks in this class here.
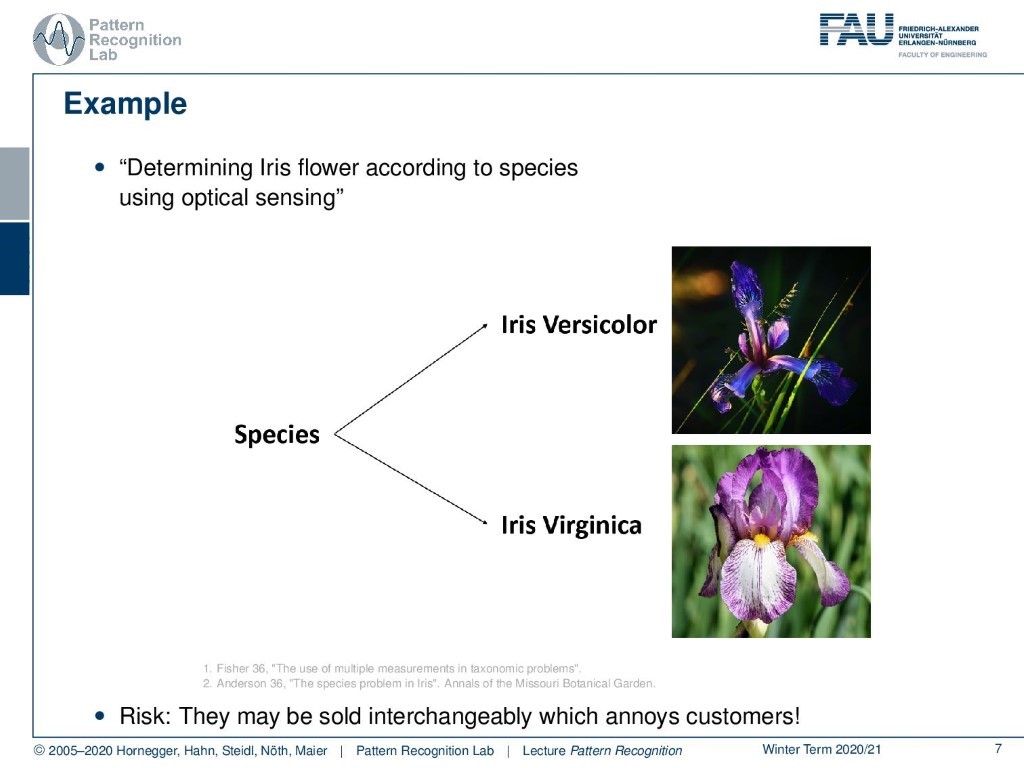
Let’s have a look at an example. We’ll try to talk about a rather simple one. Here we want to determine the kind of Iris flowers according to images. For example for this Iris, we have the Iris Versicolor and the Iris Virginica. Both of them have to be separated into two different classes because they are actually two different kinds of flowers. So here of course we have a not so risky task. If you confuse them you will not cause such great harm. But if you are actually running a flower shop you will be very much interested in this task because you might be confusing those and then your customers will become very upset. So, let’s look at an example of how you actually can extract features from the images of the flower.
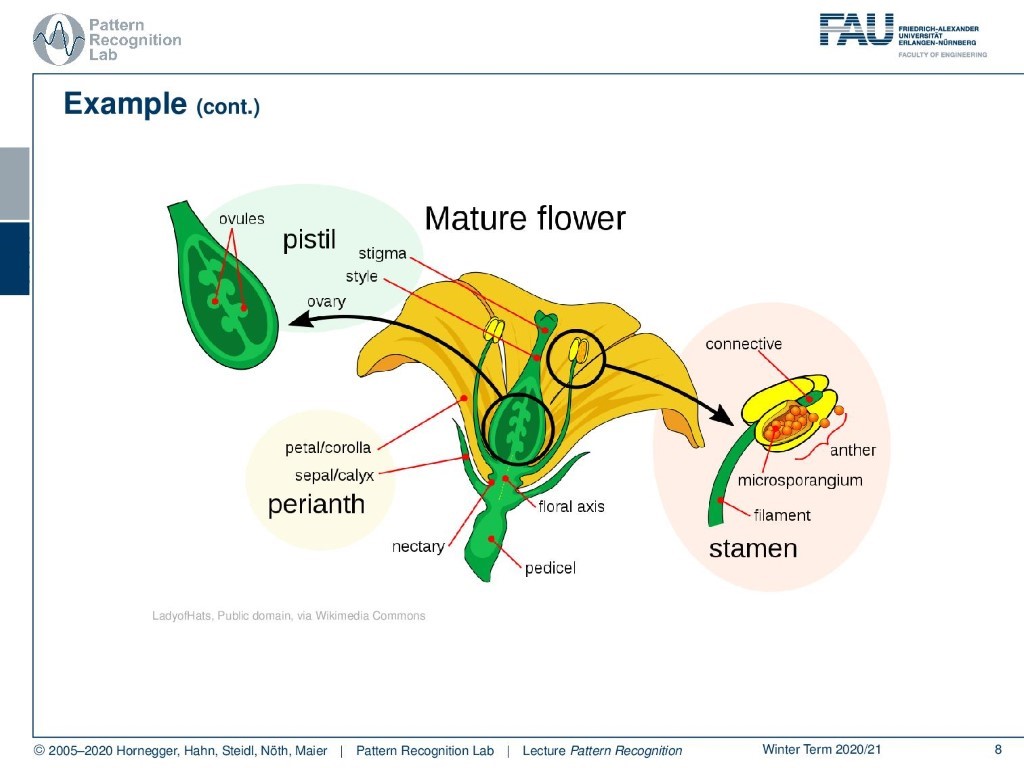
In order to do that, you have to understand a bit how flowers are actually structured. And in particular, you have different parts of the flower. We will now look into the perianth, and in particular into petal and sepal leaves, because they are very important in order to distinguish the different kinds of Iris flowers of our example.

So here you can see, that we can now kind of bring these very abstract images into a kind of vector space, where we’re able to describe those flowers. So we essentially set up the camera and take some images as you’ve seen before, and then we want to extract characteristics. And these characteristics are able to make distinctions between the different species of Iris flowers. So here you see that quite important features are sepal length, as well as sepal width. Of course the same is true for the petal leaves, so also there the length and the width are really crucial. And then of course color is a distinguishing factor in order to differentiate the different species of Iris flowers.
So now we somehow have to extract those features. In order to do that we follow our pattern recognition pipeline, so we do some pre-processing. Here, for example, it could be the segmentation operation. So we isolate the flowers from one another and also from the background. This would be the preprocessing step. Then we need some feature extraction, where we extract the best features for a single flower image. And this is, of course, a very good way of reducing the dimensionality and the data that we have to deal with. Imagine you have an image with 1024 times 1024 pixels. Then this will be already more than a million dimensions of variables that can change. And if we go to the aforementioned five features, of course, we can reduce the dimensionality of the problem a lot. This will, of course, help us building our classifiers and reducing the data dimension. So in the end, then we want to classify. And we classify these features then, this low dimensional representation of our image content, with a trained classifier.
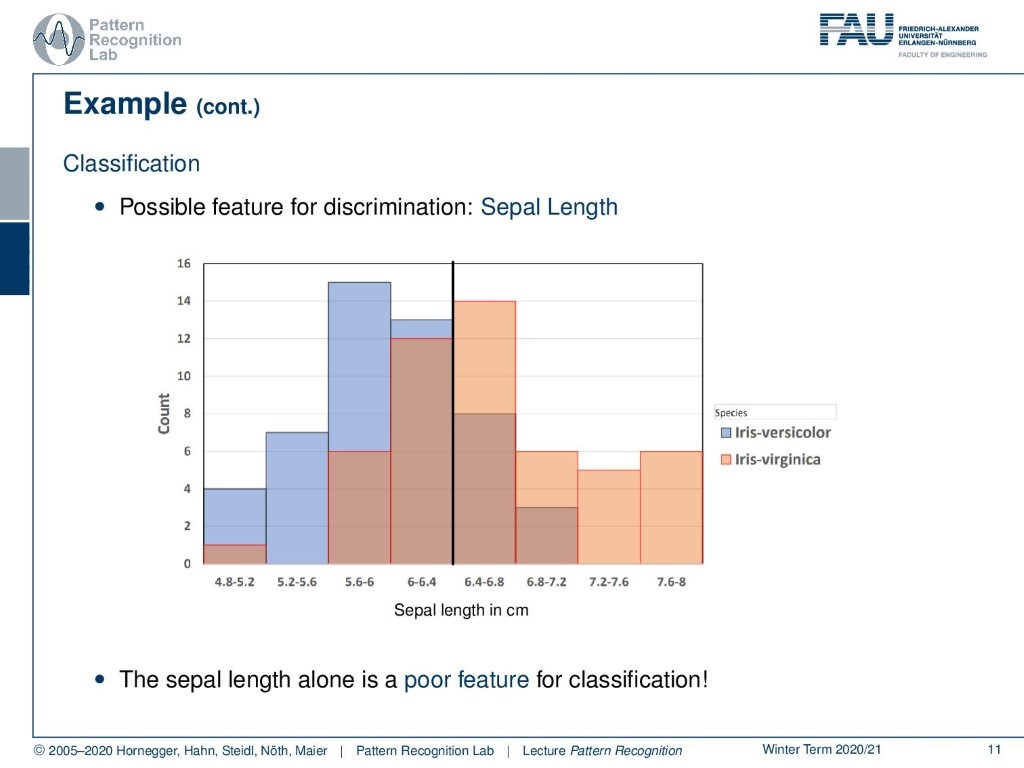
So if we do that for a certain feature, then we end up for example with the following case: we have the sepal length, and here we see the two different kinds of Iris flowers. And you see that the sepal length alone is not so great to split the two. So there is actually quite a bit of overlap between the distribution of the different lengths. This is probably not the best criterion to separate the two, but of course, it will at least allow us to separate them in some cases.
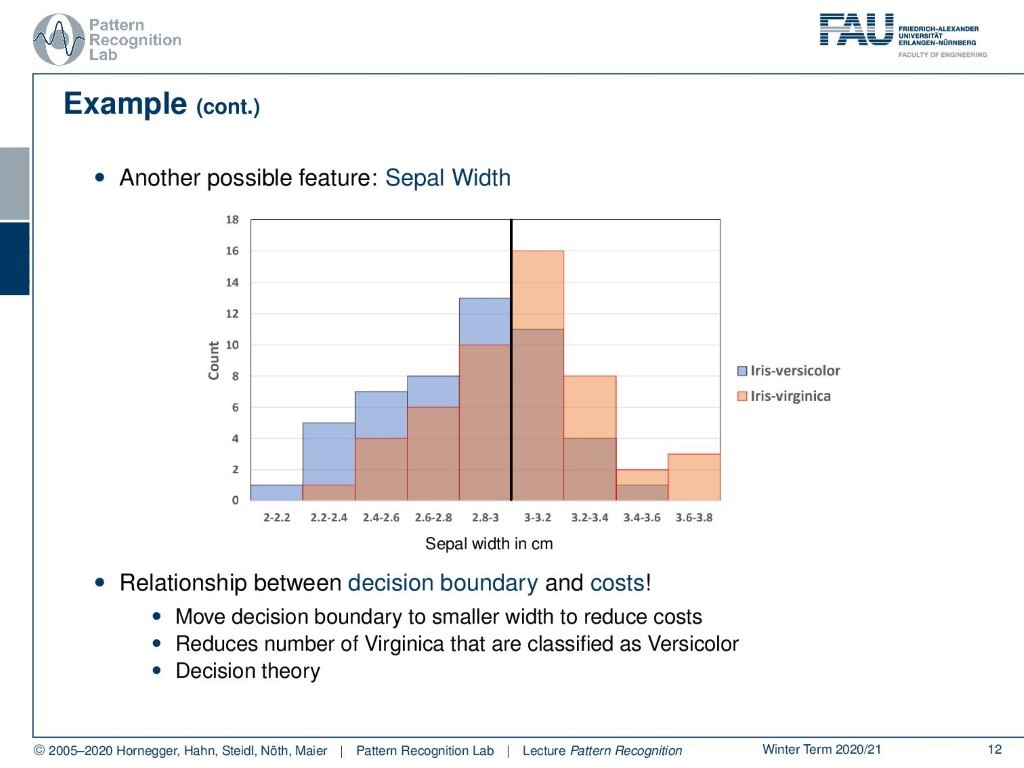
Then we can also look at different features. That could be for example the sepal width. Here you see that the overlap is even higher. So it’s rather difficult also to separate the two kinds of flowers with this kind of distribution. Now you see that when we kind of do a decision, it will essentially imply a certain risk of misclassification. And of course, if you do misclassification, you potentially incur some cost. So for example, here the cost could be a customer that is not very content. He gets angry, goes to social media, and posts really angry stuff about you. So you may want to avoid this. And actually, typically you can map also those risks into some kind of value. So if the customer is very unhappy and he starts damaging you, you can for example try to measure the cost in euros. So now we want to do of course a decision, that minimizes these misclassifications and thereby also reduces the cost.
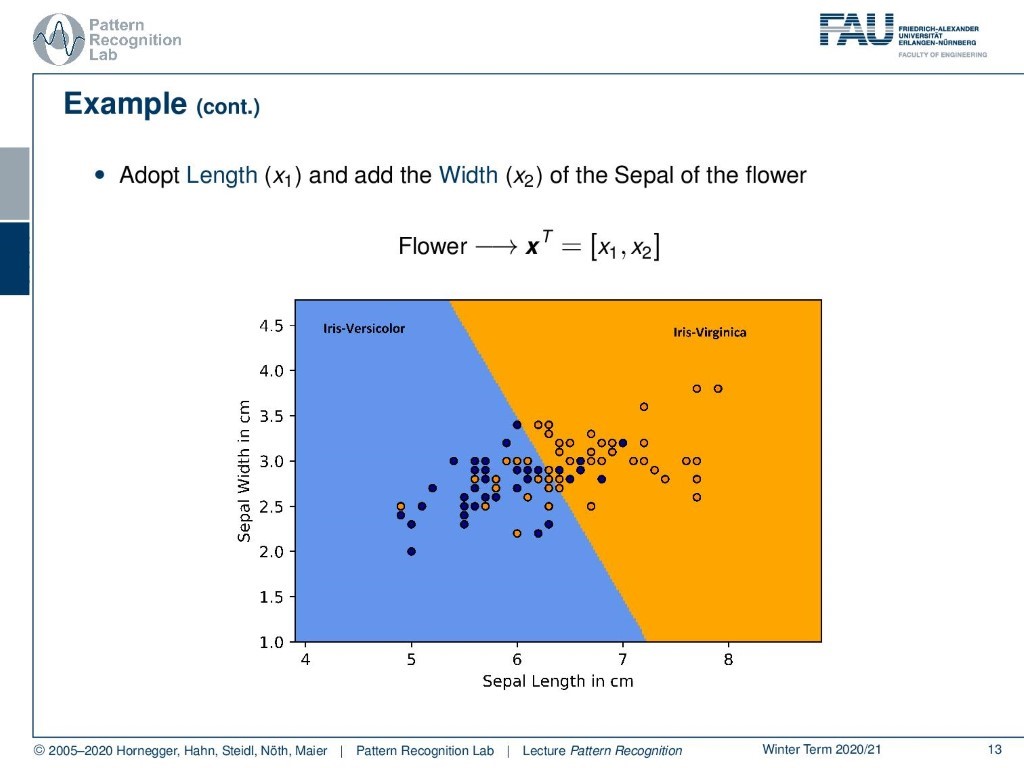
So how can we do that in a multi-dimensional space? Well, of course, we can use the two different features that we looked at and map them into a two-dimensional space. So now we are describing the different images of flowers in this kind of graph, and you can see this is a two-dimensional vector. So we have the vector x transpose that is given as x1 and x2. With x1 we are now denoting the sepal width in centimeter and with x2 we are denoting the sepal length in centimeter. So now you see that the two variables if we plot them as this kind of scatter plot kind of allow us to separate the two kinds of flowers. And you see also, that this separation here if we model this as a linear decision boundary it’s not perfect, but it kind of works.
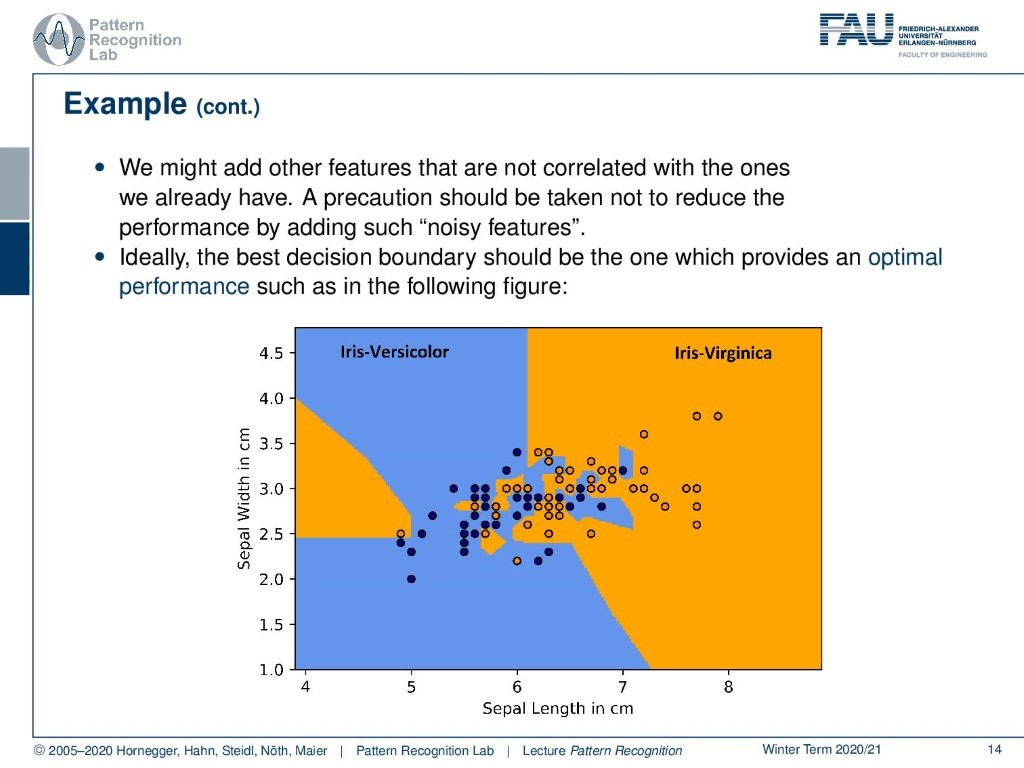
Of course, we can also choose different models. One thing that we could, for example, do is we choose simply the nearest neighbor. But if we just take the next neighboring observed data point, you see that we kind of get a very noisy kind of decision boundary. Here you can see that the direct neighbors are, of course, assigned to the respective decision. And you see these kinds of clusters appearing that are indicated here with the two colors. So this is probably not an ideal decision boundary, because in this case, the generalization is likely to be very poor. This then is also often referred to as overfitting.
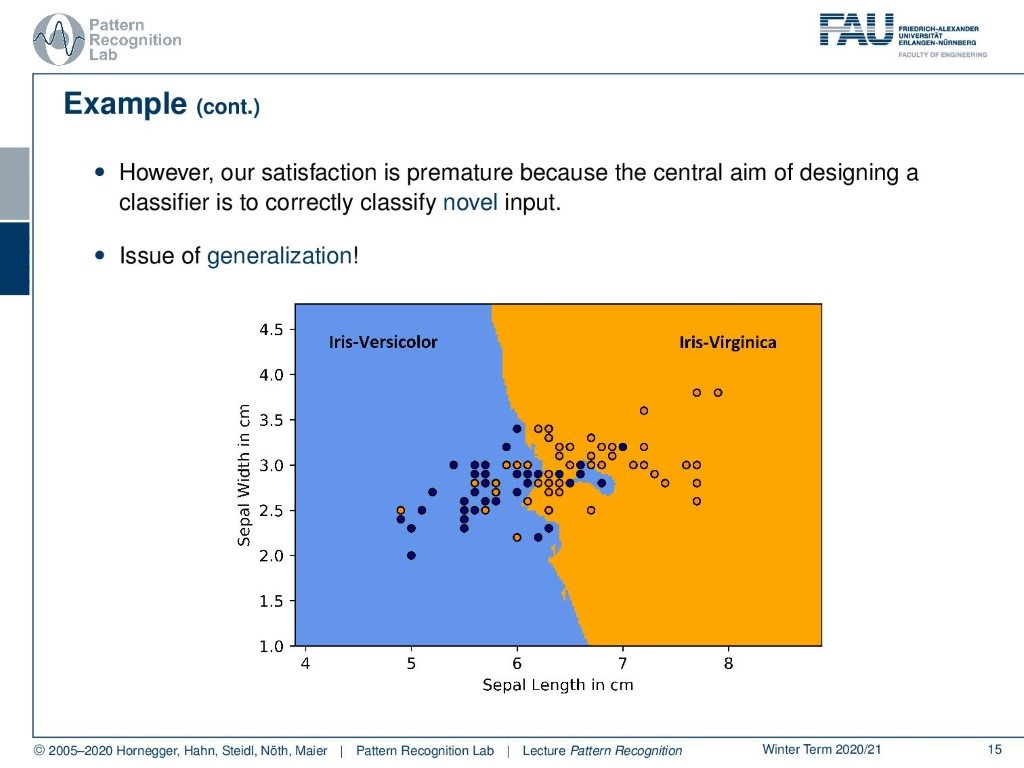
What we can do is smooth the decision. And one thing that we could do, for example, is choosing decay nearest neighbors. And then we can probably get a much more stable classification result.

So, we’ve seen now that we can deal with feature extraction. This is essentially recording the input signal. You essentially take the camera, microphone, even x-ray signal, and then you digitize it. You sample and quantize it and then you do some pre-processing and extract meaningful features. This is, actually, the topic of Introduction to Pattern Recognition. So, at this point, we assume that we already know that we are able to compute meaningful features. If you’re interested in how to compute those features, have a look at the entire class Introduction to Pattern Recognition, and there you will learn how to extract those features.

Because what we will be doing in this class and in the next video is looking into the actual classification. We will look in the next video into some postulates of Pattern Recognition. This will then be followed by many different kinds of machine learning approaches that will build on top of these feature extraction methods.
So this already brings us to the end of this first video of the introduction to our new lecture Pattern Recognition. You see that we will mainly focus on the classification methods, so the advanced methods of machine learning. The feature extraction part you can learn about in Introduction to Pattern Recognition. So let’s hope that you enjoyed this video, and I’m looking forward to seeing you again in the next one! Thank you very much and goodbye.
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep Learning Lecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced. If you are interested in generating transcripts from video lectures try AutoBlog.
References
Richard O. Duda, Peter E. Hart, David G. Stock: Pattern Classification, 2nd edition, John Wiley & Sons, New York, 2001
Trevor Hastie, Robert Tobshiani, Jerome Friedman: The Elements of Statistical Learning – Data Mining, Inference, and Prediction, 2nd edition, Springer, New York, 2009
Christopher M. Bishop: Pattern Recognition and Machine Learning, Springer, New York, 2006
H. Niemann: Klassifikation von Mustern, 2. überarbeitete Auflage, 2003