Obstacle avoidance for robotic arms is an important issue in robot control. Limited by factors such as equipment, cost, and labor, some application scenarios require the robot to have the ability to plan its own movement to reach the goal position or state. 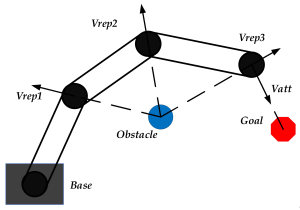 In real working environments, where obstacles’ properties are various, the traditional search algorithms are difficult to adapt to large-scale space and continuous action requirements. Artificial potential field (APF) method is a widely used obstacle avoidance path planning method, but it alsohas some shortcomings and will fall into local optimality in some special situations. Based on APF method, reinforcement learning (RL) can theoretically achieve optimization in continuous space. Combined with some modifications to traditional APF method, we define states, and actions and design the reward function, which is regarded as an important part of reinforcement learning, to form a motion planning agent in the
In real working environments, where obstacles’ properties are various, the traditional search algorithms are difficult to adapt to large-scale space and continuous action requirements. Artificial potential field (APF) method is a widely used obstacle avoidance path planning method, but it alsohas some shortcomings and will fall into local optimality in some special situations. Based on APF method, reinforcement learning (RL) can theoretically achieve optimization in continuous space. Combined with some modifications to traditional APF method, we define states, and actions and design the reward function, which is regarded as an important part of reinforcement learning, to form a motion planning agent in the
3D world, so that the robot end-effector is able to reach the goal position, emphasizing the avoidance of collision between obstacles and the whole robot arm.
Robot Movement Planning for Obstacle Avoidance using Reinforcement Learning
📋 Type
MA thesis
⚡ Status
finished
📅 Duration
Jun 3, 2024 – Nov 11, 2024
👤
Primary supervisors
Linda-Sophie Schneider
Andreas Maier
🎓 Student
Junyan Peng
Artificial Intellegence