
Written by Andreas Maier.
Deep learning is one of the most successful methods that we have seen in computer science in the last couple of years. Results indicate that many problems can be tackled with this method and amazing results are published every day. In fact, many traditional methods in pattern recognition seem obsolete. In the scientific community, lecturers in pattern recognition and signal processing discuss whether we need to redesign all of our classes as many methods do no longer reflect the state-of-the-art anymore. It seems that all of them are outperformed by methods based on deep learning.
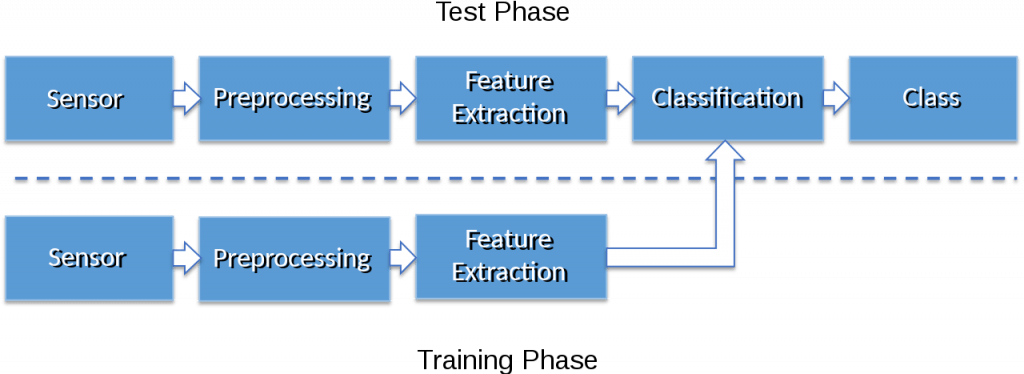
For the case of pattern recognition and machine learning in a classical sense, in which we are interested in solving a task that relies on perception, there is very little prior knowledge available, which can be exploited to solve the task efficiently. The main method that was used in classical pattern recognition, was the use of expert knowledge to identify features that are discriminative for a given task. This approach is today commonly referred to as “feature engineering”. Most of these methods have been shown to be outperformed by deep approaches that sketch a certain algorithm blueprint within an architecture design and train all parameters in a data-driven way. Doing so, we are able to approach or even surpass human performance in many problems.
One major goal that all of these “perceptual tasks” share, is that we are not able to truly understand how the human brain is solving them. Hence, building deep networks that offer significant degrees of freedom on how to approach the problems gives us the best results. I am not aware of any better approach to deal with this fundamental restriction yet.
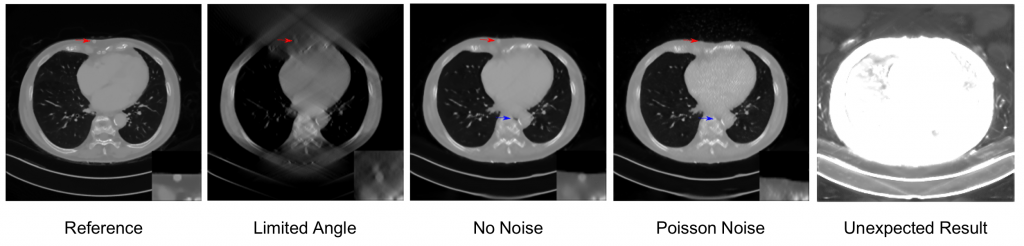
Given this tremendous success, it is not surprising to see that many researchers began to apply deep learning to tasks in classical signal processing. This ranges from noise reduction in hearing aids, over image super-resolution, up to 3D volumetric image reconstruction in medical imaging modalities such as computed tomography. In fact, many papers demonstrate that deep learning is able to outperform classical methods for many given task domains. In the best case, these networks learn variants of classical algorithms that are optimized towards a certain application. In other cases, we even see amazing results although the network architecture is mathematically not able to model the true underlying function. Yet, on a limited application domain, the task is still approximated well for a variety of problems given appropriate training data.
As neural networks are universal function approximators, these results are not entirely surprising. Still one may wonder whether we really need to learn all of the trainable parameters from scratch if we already know e.g. for the case of magnetic resonance imaging (MRI) that the processing chain must contain a Fourier transform. In fact, a recent paper proposes the concept of „known operator learning“ that investigates the effect of integration of such known operators like the Fourier transform in MRI. The paper demonstrates that the inclusion of the operation into the network, in fact, reduces the maximum error bounds of the learning problem. Hence, the knowledge helps to find a more stable solution and at the same time reduces the number of trainable parameters. In most cases, this also yields a reduction of the required amount of training samples.

A prerequisite that is important to mention at this point is that any operation that allows the computation of a gradient/derivative with respect to the input data and optionally with respect to its parameters is suited to be used in this framework. As such „operators“ can range from simple matrix multiplications to sophisticated methods like entire ray-tracers e.g. in computer graphics. Even highly non-linear methods like the median filter allow computing linearised gradients that enable their use within this framework.
So far, „known operator learning“ has been applied to construct networks that unite deep learning methods with classical signal processing. It can be used to design efficient and interpretable reconstruction methods for computed tomography, integrate physics into X-ray material decomposition, and reduce the number of parameters in segmentation and denoising networks. We have even seen that the fusion of deep learning and classical theory is able to „derive“ new network structures in a mathematical sense. In doing so, a new mathematical image rebinning formula was discovered which was previously unknown. This new formula now allows mapping parallel MRI raw data into an X-ray acquisition geometry. This new discovery was a fundamental step towards new MRI/X-ray hybrid scanners any may pave the way towards an entirely new generation of medical scanners.

In fact, one may argue that we are using this concept for quite some time in deep learning already. In principle, convolutional and pooling layers are known operators that are inspired by neural processing in the brain. Hence, one could argue that their inclusion is a kind of prior knowledge that should be present in the network. However, in contrast to the X-ray and MRI examples, we do not have any guarantee that the operator needs to be present in the network. Still, these observations are very well in line with the results that deep learning produces every day.
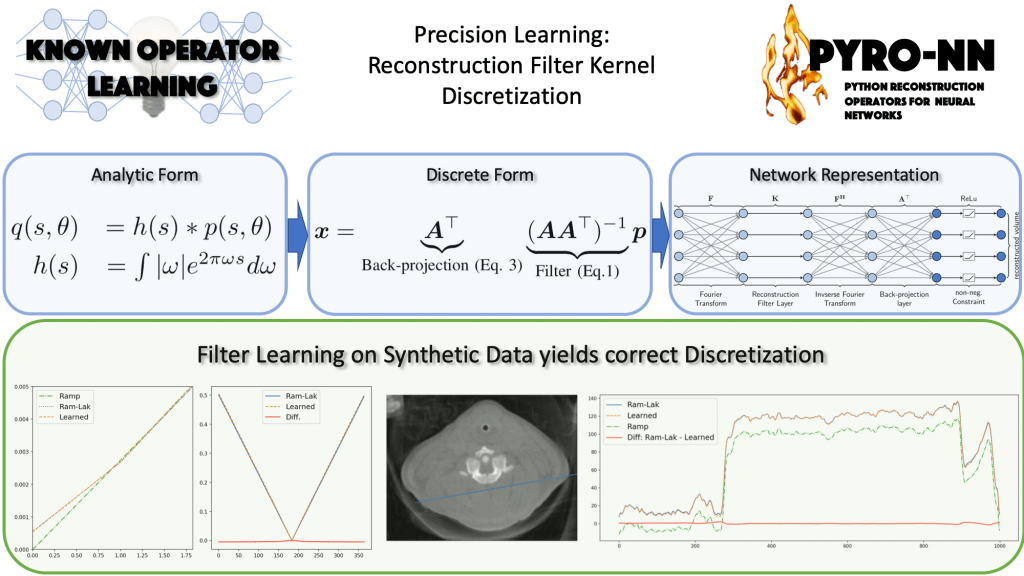
Based on these findings, I do not believe that we should omit classical theory in our classes and replace them with lectures on deep learning only. In fact, I do believe that classical theory and deep learning are very well compatible and can be used to facilitate understanding of each other. On the one hand, we have observed evidence that e.g. noise augmentation techniques resemble Wiener filters and that end-to-end discrete filter networks can learn correct filter discretization from very few training examples. So deep learning helps to simplify practical problems in classical theory. On the other hand, we also see that we can replace blocks with classical operations in deep networks to understand their purpose. This restricts the solution space of the network and allows us to analyze their simpler parts with methods from classical theory. Hence, deep learning can also benefit from traditional approaches. In fact, I believe that this fusion of both worlds is an excellent direction for future research and may enable us to unite the domains of symbolic processing and deep learning methods in the future. Hence, we need to continue to convey classical methods, but we need to put them into the right context and connect them to the appropriate deep methods.
If you liked this essay, you can find an extended version of this view in “A Gentle Introduction to Deep Learning in Medical Image Processing“ or have a look at my YouTube Channel. This article originally appeared first on MarkTechPost.com and is released under the Creative Commons 4.0 Attribution License.