
Self-Supervised Labels
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning“. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. Try it yourself! If you spot mistakes, please let us know!

Welcome back to deep learning! So today, we want to start talking about ideas that are called self-supervised learning. We want to obtain labels by self-supervision and will look into what this term actually means, what the core ideas are in the next couple of videos.
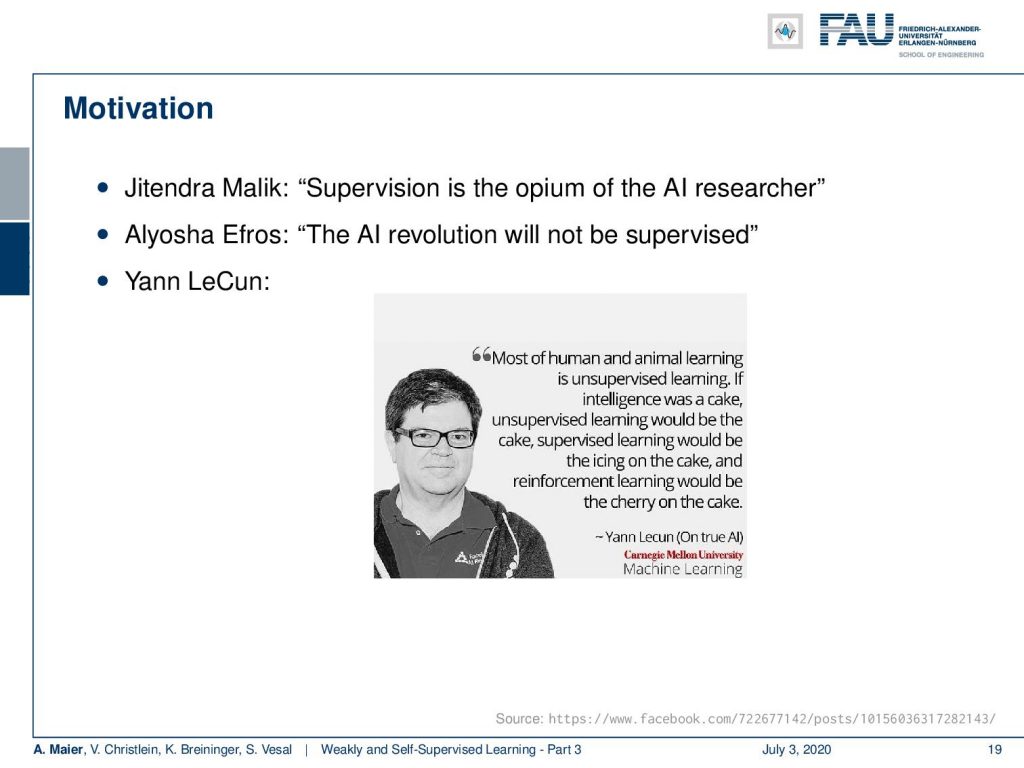
So, this is part three of weakly and self-supervised learning. Today, we actually start talking about self-supervised learning. There are a couple of views around self-supervised learning and you can essentially split them into two parts. You can say, one is how to get the self-supervised labels and the other part is that you work on the losses in order to embed those labels. We have particular losses that are suited for the self-supervision. So, let’s start with the definition. The motivation is you could say that classically people in machine learning believed that supervision is, of course, the approach that produces the best results. But, we have these massive amounts of labels that we need. So, you could actually very quickly then come to the conclusion that the AI revolution will not be supervised. This is very clearly visible in the following statement by Yann LeCun. “Most of human and animal learning is unsupervised learning. If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.” Of course, this is substantiated by observations in biology and how humans and animals learn.

The idea of self-supervision is that you try to use information that you already have about your problem to come up with some surrogate labels that allow you to do training processes. The key ideas here on this slide by Yann LeCun can be summarized as follows: You try to predict the future from the past, you can predict the future also from the recent past, you predict the past from the present or the top from the bottom. Also, an option could be to predict the occluded from the visible. You pretend that there is a part of the input that you don’t know and predict that. This essentially allows you to come up with a surrogate task. With the surrogate task, you can already perform training. The nice thing is you don’t need any label at all because you intrinsically use the structure of the data.

Essentially, self-supervised learning is an unsupervised learning approach. But every now and then, you need to make clear that you’re doing something new in a domain that has been researched on for many decades. So, you may not refer to the term unsupervised anymore and Yann LeCun actually proposed the term self-supervised learning. He realized that unsupervised is a loaded and confusing term. So although the ideas have already been around before, the term self-supervised learning has been established. It makes sense to use this term to concentrate on a particular kind of unsupervised learning. So, you could say it’s a subcategory of unsupervised learning. It uses pretext surrogates of pseudo tasks in a supervised fashion. This essentially means you can use all of the supervised learning methods and you have labels that are automatically generated. They can then be used as a measurement of correctness to create a loss in order to train your weights. The idea is then that this is beneficial for downstream tasks like retrieval, supervised, or semi-supervised classification, and so on. By the way in this kind of broad definition, you could also argue that generative models like generative adversarial networks are also some kind of self-supervised learning method. So essentially, Yann LeCun had this very nice idea to frame this kind of learning in a new way. If you do so, this is, of course, very helpful because you can make clear that you’re doing something new and you’re different from the many unsupervised learning approaches that have been out there for a very long time.
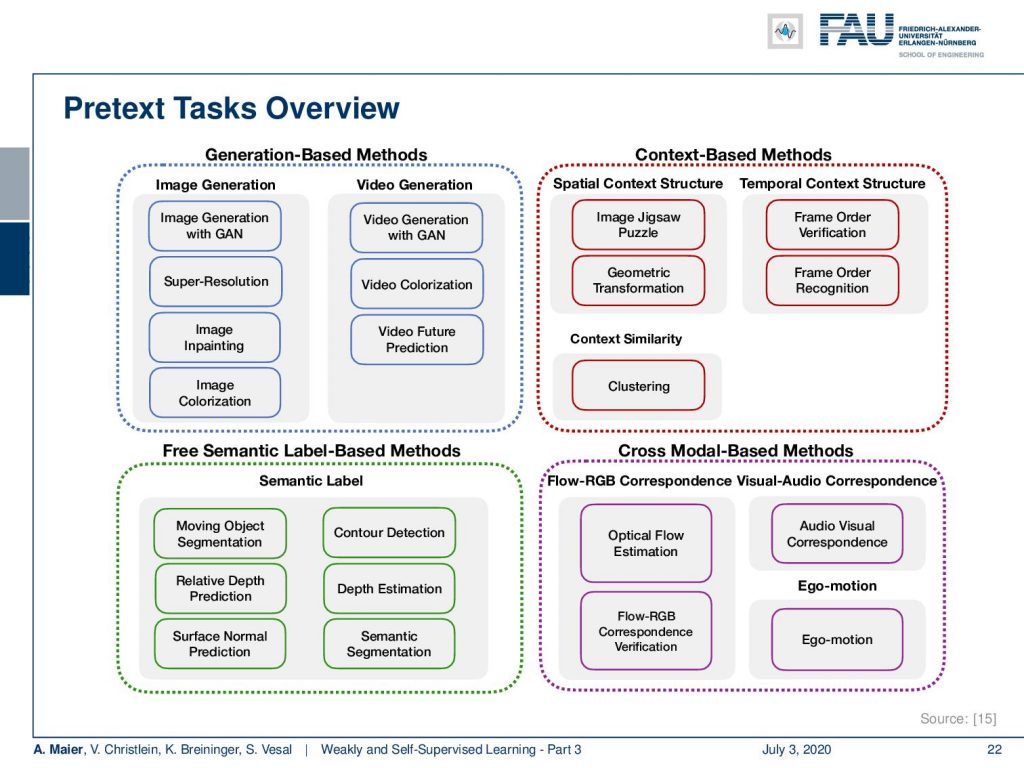
So, let’s look into some of these ideas. There are, of course, these pretext tasks and you can work with generation-based methods. So, you can use GANs, you can do things like super-resolution approaches. There, you downsample and try to predict the higher resolution image. You can do inpainting approaches or colorization. Of course, this also works with videos. You can work with context-based methods. Here, you try to solve things like the jigsaw puzzle or clustering. In semantic label-based methods, you can do things like trying to estimate moving objects or predict the relative depth. Then there’s also cross-modal methods where you try to use information from more than one modality. You have a linked sensor system, let’s say you have a depth camera and an RGB camera. Then, you can link the two and try to predict the one from the other. If you have an attached sensor, let’s say you have a car, you’re moving, and you have a GPS sensor or any other sensory system that will tell you how your car is moving, then you can try to predict the ego-motion from the actual video sequence.

So let’s look into this in a bit of more detail and look at image-based self-supervised learning techniques to refine representation learning, the first idea, the generative ones. You can for example do image colorization where it is very easy to generate labels.

You start with color images, compute essentially the average over the channels that gives you a gray value image. Then, you try to predict the original color again. You can use a kind of scene and encoder/decoder approach in order to predict the correct color maps.

Furthermore, you can also go into inpainting. You can occlude parts of the image and then try to predict those. This then essentially results in the task that you try to predict a complete image where you then compare to the actual full image to the prediction that was created by your generator. You can train these things for example in a GAN-type of loss setting. We have a discriminator that then tells you whether this was a good inpainting result or not.

There are also ideas about spatial context. Here, a very common approach is to solve a jigsaw puzzle. You take a patch or actually, you take nine patches of the image and you essentially try to predict whether you have the center patch, let’s say, for the face of the cat here, you have one. Then, you want to predict what is the ID of the patch that is shown. So, you put in two images and try to predict the correct location of the second patch. Notice that this is a bit tricky because there is a trivial solution possible. This happens if you have boundary patterns that are continuing. If you have continuing textures, then it may occur that the actual patch can very easily be detected in the next patch because the texture is continued. So, you should use large enough gaps in order to get around this problem. Color may be tricky too. You can use chromatic aberration and pre-process the images by shifting green and magenta towards gray, or you randomly drop two of the color channels in order to avoid that you’re only learning about color.
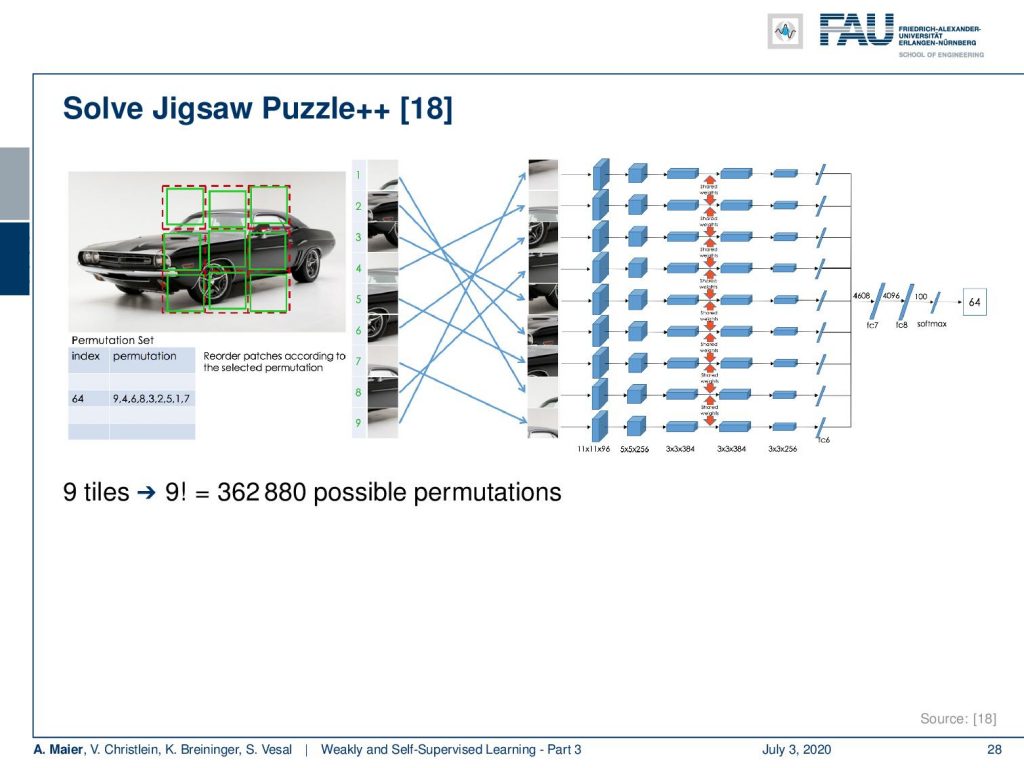
There’s an improved version of the jigsaw puzzle. In jigsaw puzzle++, the idea is that you essentially randomize the order of the patches and you try to predict the correct location of each patch. Now, the cool thing about this is if you have 9 tiles then you have 9! possible permutations. This is more than 300-thousand. So, we can create plenty of labels for this task and you see that it’s actually key that you do it in the right way. So, it’s not just that you have a lot of permutations.
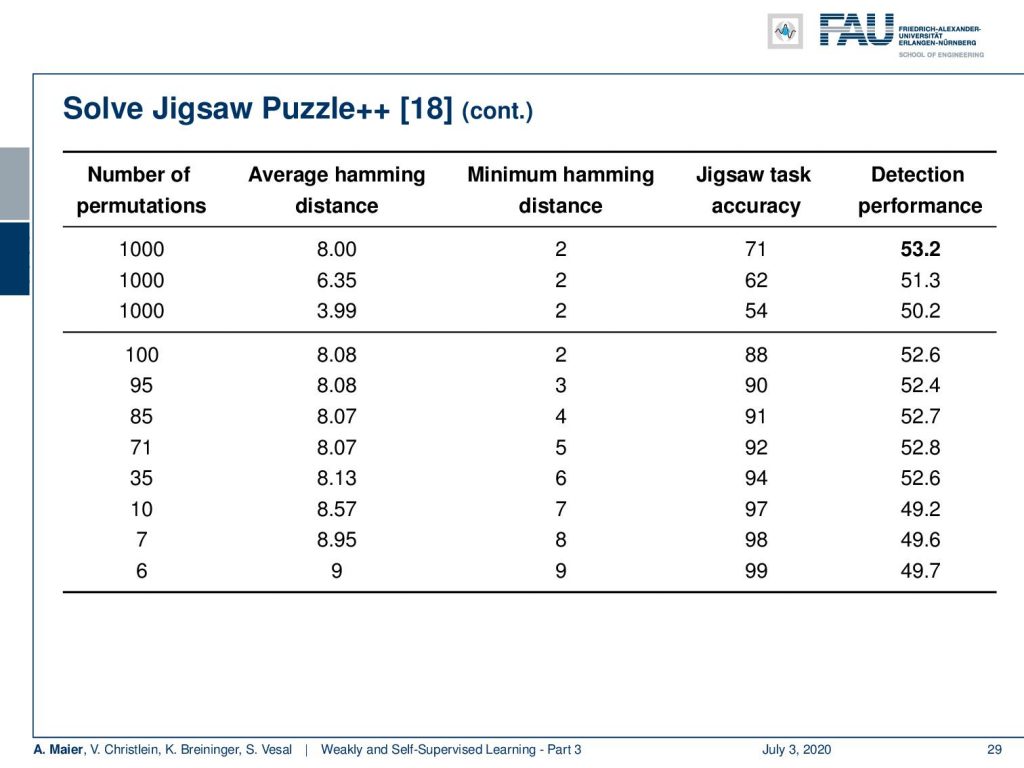
You also want to make sure that there is an appropriate average Hamming distance. You can see if you actually obey this idea, then this makes a difference. If you have a too low average Hamming distance, the jigsaw task accuracy is not very high. If you increase it, the jigsaw task accuracy also increases. There’s a very high likelihood that this high accuracy then will also go to the actual task of interest. So here, this is a detection task and with a high jigsaw task accuracy, you also build a better detector.
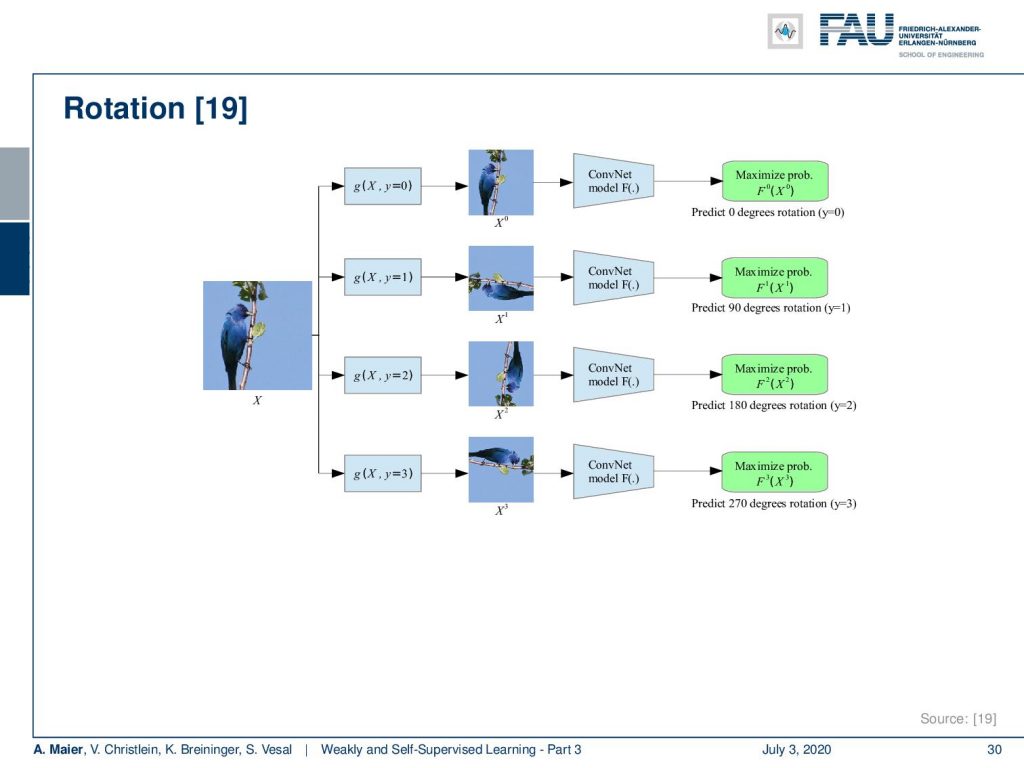
Well, which other ideas could we be interested in? Of course, you can do similar things with rotation. Then, you try to predict the correct rotation of the image. This is also a very cheap label that you can generate.

Let’s look a bit into context similarity. Here, the idea is that you want to figure out whether this image is from the same or a different context. So, you can pick an input patch, then you augment it. You use different ways of augmentation like changes in color contrast, slight movement, and general pixel transformations: You can also add noise and this gives you essentially for every patch a large number of other patches that should show the same content. Now, you can repeat that with other patches and this allows you to build a large database. With those patches, you can then train whether it’s the same patch or not, and you can then discriminate these several good classes and train your system similarly.
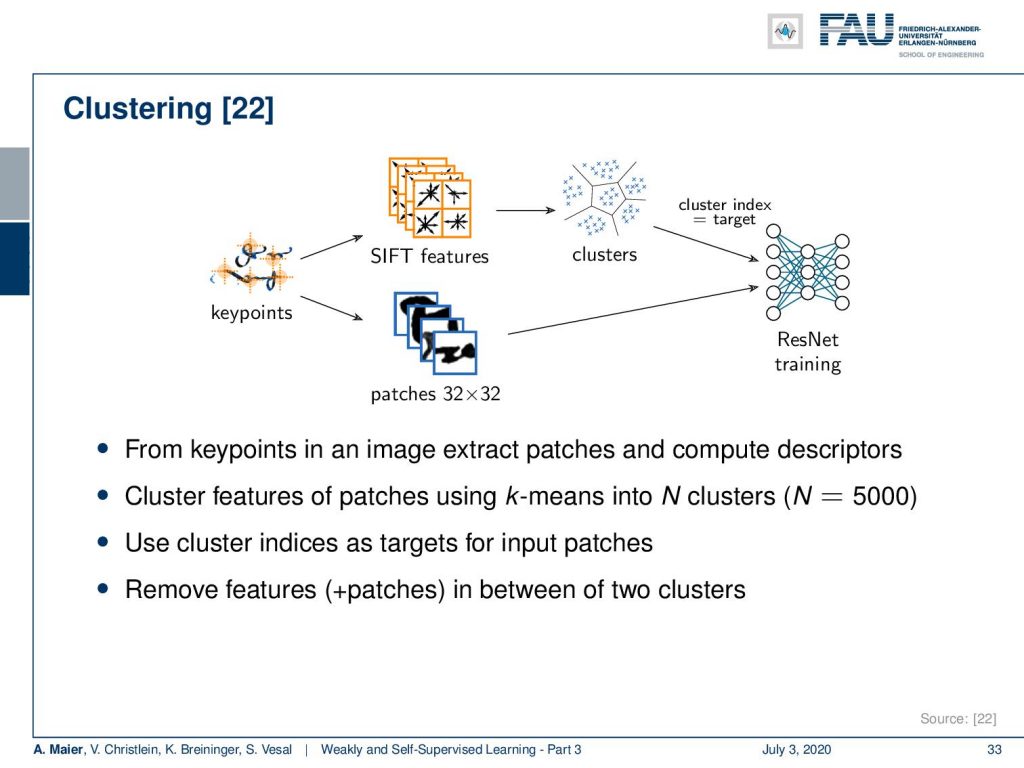
A different approach is that you use clustering. This is work by my colleague Vincent Christlein. He was interested in building better features for writer identification. So, he started with detecting key points. The key points then allow you to extract patches. At the same time, the key points if detected with algorithms like SIFT, come with a feature descriptor. On the future descriptor, you can then perform clustering and the clusters that you get are probably already quite good training samples. So, you use the cluster-ID in order to train for example a ResNet for the prediction of the respective patch. This way, you can use a completely unlabeled data set, do the clustering, generate pseudo labels, and train your system. Vincent has shown that this actually gives quite a bit of performance in order to improve representation learning.
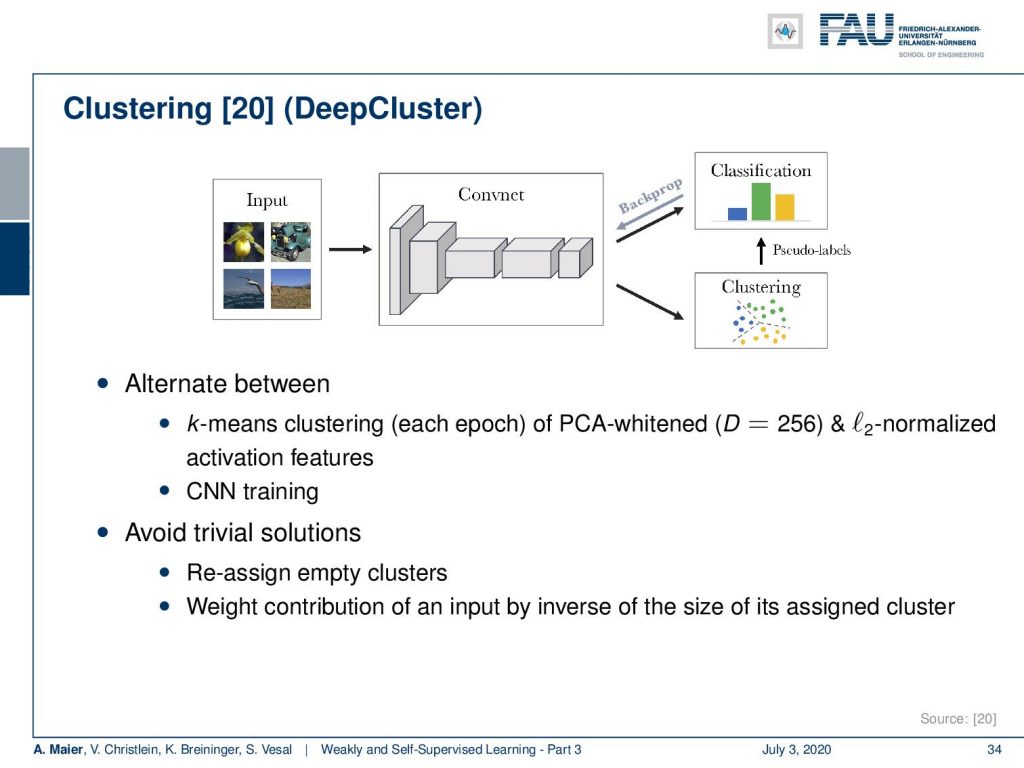
This idea has then been developed further. You can do it in an alternating manner. This idea is called DeepCluster. Now, you take some input, you have a convnet, and you then essentially start from an untrained Network. You do clustering on the generated features and with the clustering, e.g. simply k-means, you can then generate pseudo labels that allow backpropagation and the training of the representation learning. Now, of course, if you start with random initialization, the clustering is probably not very good. So, you want to alternate between the classification and the clustering. Then, this allows you to build also a very powerful convolutional neural network. There are also some problems with trivial solutions that you want to avoid. So, you want to reassign empty clusters and, of course, you can use tricks like weighting the contribution of an input by the inverse of the size of its assigned cluster.
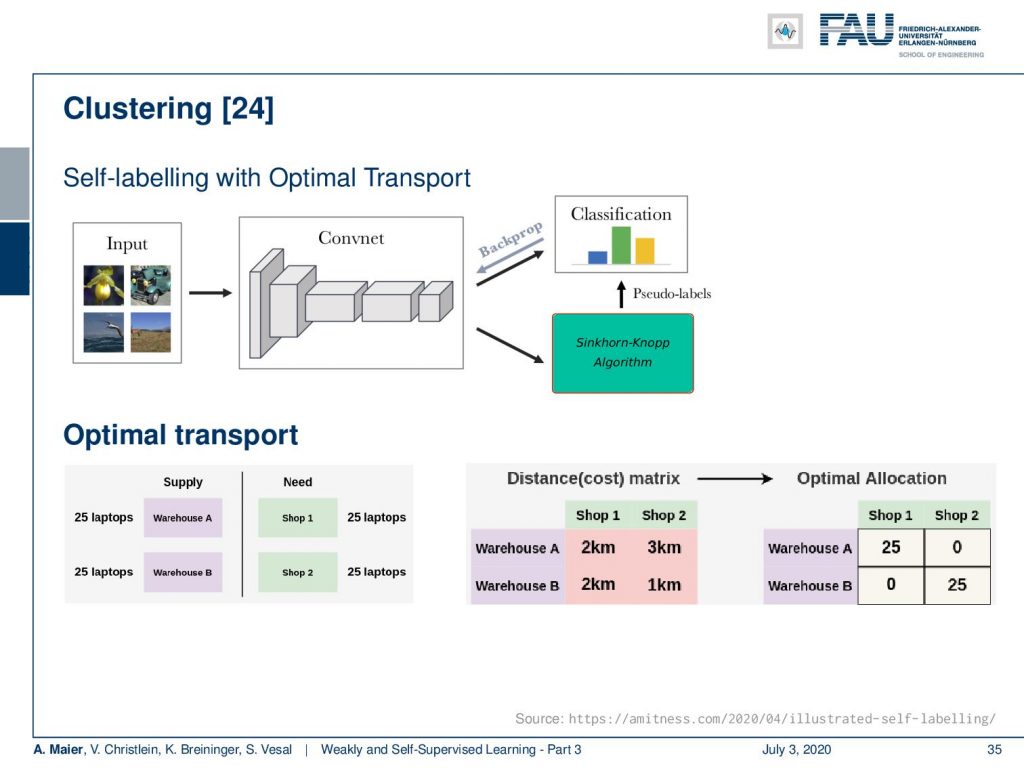
You can even build on this idea further. This leads to self-labeling with optimal transport in [24]. Here, they essentially further developed DeepCluster. Instead of using clustering, they’re using the Sinkhorn-Knopp algorithm in order to determine pseudo labels. The idea here is that you try to predict the optimal transport. Here, we can see this example of an optimal transport problem. Let’s say, you have supplies in Warehouse A and Warehouse B. Each of them have 25 laptops and you have a need in each of Shop 1 and Shop 2 of 25 laptops. Then, you can see that you want to ship those laptops to the respective shops. Of course, you take the closest one and all of the laptops from Warehouse A in this case go to Shop 1 and all of the laptops of Warehouse B go to Shop 2.

The nice thing about this algorithm is that you can find a linear version of this. So, you can essentially express all of this with linear algebra and then this means that you can also embed it into a neural network. If you compare DeepCluser to the optimal transport, then you may want to keep in mind if you don’t have a separate clustering loss, this can lead to degenerate solutions. Also, keep in mind that the clustering approach minimizes the same cross-entropy loss that the network also seeks to optimize.

Well, there’s a couple of more ideas. We know these recipes like multi-task learning. You can also do multi-task learning for self-supervised learning. An example here is that you use synthetic imagery. So, you have some synthetic images where you can generate the depth, the surface normal, or also the contours. Then, you can use those as labels in order to train your network and produce a good representation. Additionally, you can also minimize the feature space domain differences between real and synthetic data in a kind of GAN setup. This leads also to very good representation learning.

Next time, we want to talk about ideas on how to work with the losses and make them more suited towards the self-supervised learning task. We will see that in particular, the contrastive losses are very useful for this. So, thank you very much for listening and see you in the next video. Bye-bye!

If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced. If you are interested in generating transcripts from video lectures try AutoBlog.
References
[1] Özgün Çiçek, Ahmed Abdulkadir, Soeren S Lienkamp, et al. “3d u-net: learning dense volumetric segmentation from sparse annotation”. In: MICCAI. Springer. 2016, pp. 424–432.
[2] Waleed Abdulla. Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow. Accessed: 27.01.2020. 2017.
[3] Olga Russakovsky, Amy L. Bearman, Vittorio Ferrari, et al. “What’s the point: Semantic segmentation with point supervision”. In: CoRR abs/1506.02106 (2015). arXiv: 1506.02106.
[4] Marius Cordts, Mohamed Omran, Sebastian Ramos, et al. “The Cityscapes Dataset for Semantic Urban Scene Understanding”. In: CoRR abs/1604.01685 (2016). arXiv: 1604.01685.
[5] Richard O. Duda, Peter E. Hart, and David G. Stork. Pattern classification. 2nd ed. New York: Wiley-Interscience, Nov. 2000.
[6] Anna Khoreva, Rodrigo Benenson, Jan Hosang, et al. “Simple Does It: Weakly Supervised Instance and Semantic Segmentation”. In: arXiv preprint arXiv:1603.07485 (2016).
[7] Kaiming He, Georgia Gkioxari, Piotr Dollár, et al. “Mask R-CNN”. In: CoRR abs/1703.06870 (2017). arXiv: 1703.06870.
[8] Sangheum Hwang and Hyo-Eun Kim. “Self-Transfer Learning for Weakly Supervised Lesion Localization”. In: MICCAI. Springer. 2016, pp. 239–246.
[9] Maxime Oquab, Léon Bottou, Ivan Laptev, et al. “Is object localization for free? weakly-supervised learning with convolutional neural networks”. In: Proc. CVPR. 2015, pp. 685–694.
[10] Alexander Kolesnikov and Christoph H. Lampert. “Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation”. In: CoRR abs/1603.06098 (2016). arXiv: 1603.06098.
[11] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, et al. “Microsoft COCO: Common Objects in Context”. In: CoRR abs/1405.0312 (2014). arXiv: 1405.0312.
[12] Ramprasaath R. Selvaraju, Abhishek Das, Ramakrishna Vedantam, et al. “Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization”. In: CoRR abs/1610.02391 (2016). arXiv: 1610.02391.
[13] K. Simonyan, A. Vedaldi, and A. Zisserman. “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps”. In: Proc. ICLR (workshop track). 2014.
[14] Bolei Zhou, Aditya Khosla, Agata Lapedriza, et al. “Learning deep features for discriminative localization”. In: Proc. CVPR. 2016, pp. 2921–2929.
[15] Longlong Jing and Yingli Tian. “Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey”. In: arXiv e-prints, arXiv:1902.06162 (Feb. 2019). arXiv: 1902.06162 [cs.CV].
[16] D. Pathak, P. Krähenbühl, J. Donahue, et al. “Context Encoders: Feature Learning by Inpainting”. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016, pp. 2536–2544.
[17] C. Doersch, A. Gupta, and A. A. Efros. “Unsupervised Visual Representation Learning by Context Prediction”. In: 2015 IEEE International Conference on Computer Vision (ICCV). Dec. 2015, pp. 1422–1430.
[18] Mehdi Noroozi and Paolo Favaro. “Unsupervised Learning of Visual Representations by Solving Jigsaw Puzzles”. In: Computer Vision – ECCV 2016. Cham: Springer International Publishing, 2016, pp. 69–84.
[19] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. “Unsupervised Representation Learning by Predicting Image Rotations”. In: International Conference on Learning Representations. 2018.
[20] Mathilde Caron, Piotr Bojanowski, Armand Joulin, et al. “Deep Clustering for Unsupervised Learning of Visual Features”. In: Computer Vision – ECCV 2018. Cham: Springer International Publishing, 2018, pp. 139–156. A.
[21] A. Dosovitskiy, P. Fischer, J. T. Springenberg, et al. “Discriminative Unsupervised Feature Learning with Exemplar Convolutional Neural Networks”. In: IEEE Transactions on Pattern Analysis and Machine Intelligence 38.9 (Sept. 2016), pp. 1734–1747.
[22] V. Christlein, M. Gropp, S. Fiel, et al. “Unsupervised Feature Learning for Writer Identification and Writer Retrieval”. In: 2017 14th IAPR International Conference on Document Analysis and Recognition Vol. 01. Nov. 2017, pp. 991–997.
[23] Z. Ren and Y. J. Lee. “Cross-Domain Self-Supervised Multi-task Feature Learning Using Synthetic Imagery”. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. June 2018, pp. 762–771.
[24] Asano YM., Rupprecht C., and Vedaldi A. “Self-labelling via simultaneous clustering and representation learning”. In: International Conference on Learning Representations. 2020.
[25] Ben Poole, Sherjil Ozair, Aaron Van Den Oord, et al. “On Variational Bounds of Mutual Information”. In: Proceedings of the 36th International Conference on Machine Learning. Vol. 97. Proceedings of Machine Learning Research. Long Beach, California, USA: PMLR, Sept. 2019, pp. 5171–5180.
[26] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, et al. “Learning deep representations by mutual information estimation and maximization”. In: International Conference on Learning Representations. 2019.
[27] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. “Representation Learning with Contrastive Predictive Coding”. In: arXiv e-prints, arXiv:1807.03748 (July 2018). arXiv: 1807.03748 [cs.LG].
[28] Philip Bachman, R Devon Hjelm, and William Buchwalter. “Learning Representations by Maximizing Mutual Information Across Views”. In: Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 2019, pp. 15535–15545.
[29] Yonglong Tian, Dilip Krishnan, and Phillip Isola. “Contrastive Multiview Coding”. In: arXiv e-prints, arXiv:1906.05849 (June 2019), arXiv:1906.05849. arXiv: 1906.05849 [cs.CV].
[30] Kaiming He, Haoqi Fan, Yuxin Wu, et al. “Momentum Contrast for Unsupervised Visual Representation Learning”. In: arXiv e-prints, arXiv:1911.05722 (Nov. 2019). arXiv: 1911.05722 [cs.CV].
[31] Ting Chen, Simon Kornblith, Mohammad Norouzi, et al. “A Simple Framework for Contrastive Learning of Visual Representations”. In: arXiv e-prints, arXiv:2002.05709 (Feb. 2020), arXiv:2002.05709. arXiv: 2002.05709 [cs.LG].
[32] Ishan Misra and Laurens van der Maaten. “Self-Supervised Learning of Pretext-Invariant Representations”. In: arXiv e-prints, arXiv:1912.01991 (Dec. 2019). arXiv: 1912.01991 [cs.CV].
33] Prannay Khosla, Piotr Teterwak, Chen Wang, et al. “Supervised Contrastive Learning”. In: arXiv e-prints, arXiv:2004.11362 (Apr. 2020). arXiv: 2004.11362 [cs.LG].
[34] Jean-Bastien Grill, Florian Strub, Florent Altché, et al. “Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning”. In: arXiv e-prints, arXiv:2006.07733 (June 2020), arXiv:2006.07733. arXiv: 2006.07733 [cs.LG].
[35] Tongzhou Wang and Phillip Isola. “Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere”. In: arXiv e-prints, arXiv:2005.10242 (May 2020), arXiv:2005.10242. arXiv: 2005.10242 [cs.LG].
[36] Junnan Li, Pan Zhou, Caiming Xiong, et al. “Prototypical Contrastive Learning of Unsupervised Representations”. In: arXiv e-prints, arXiv:2005.04966 (May 2020), arXiv:2005.04966. arXiv: 2005.04966 [cs.CV].