
Motivation & High Profile Applications
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning“. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!
Welcome everybody to this semester’s deep learning lecture! As you can see I’m not in the lecture hall. Like many of you, I am in my home office and we have to work from home in order to stop the current pandemic.
Therefore, I decided to record these lectures and then also make them available on the Internet such that everybody can use them freely. You will see that we did a couple of changes to this format. First of all, we reduced the length of the lectures. We no longer go for 90 minutes in a row. Instead, we decided to reduce the length into smaller parts such that you can watch them in 15 to 30 minutes in one go, then stop and then continue to the next lecture. This means that we had to introduce a couple of changes. Of course, as every semester, we also updated all of the contents such that we really present the state-of-the-art that is up-to-date to current research.
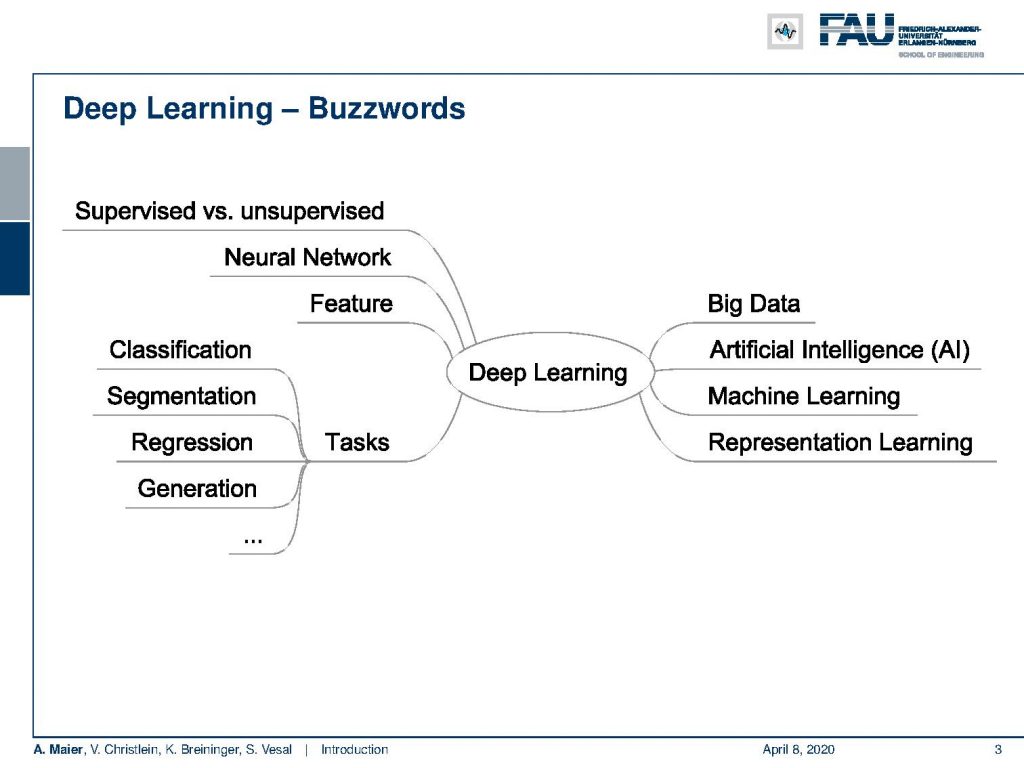
This first lecture will be about the introduction into deep learning we will deal with a broad variety of topics in this lecture – first and foremost, of course, deep learning. We summarized some of the buzzwords here that you may have already heard. We cover topics from supervised to unsupervised learning. Of course, we talk about neural networks, feature representation, feature learning, big data, artificial intelligence, machine representation learning, but also different tasks such as classification, segmentation, regression, and generation.

Let’s have a short look at the outline. So first, we’ll start with a motivation why we are interested in deep learning. We see that we have seen tremendous progress over the last couple of years, so it will be very interesting to look into some applications and some breakthroughs that have been done. Then in the next videos, we want to talk about machine learning and pattern recognition and how they are related to deep learning. And of course in the first set of lectures, we also want to start from the very basics. We will talk about the perceptron and we also have to talk about a couple of organizational matters that you will see in video number five.
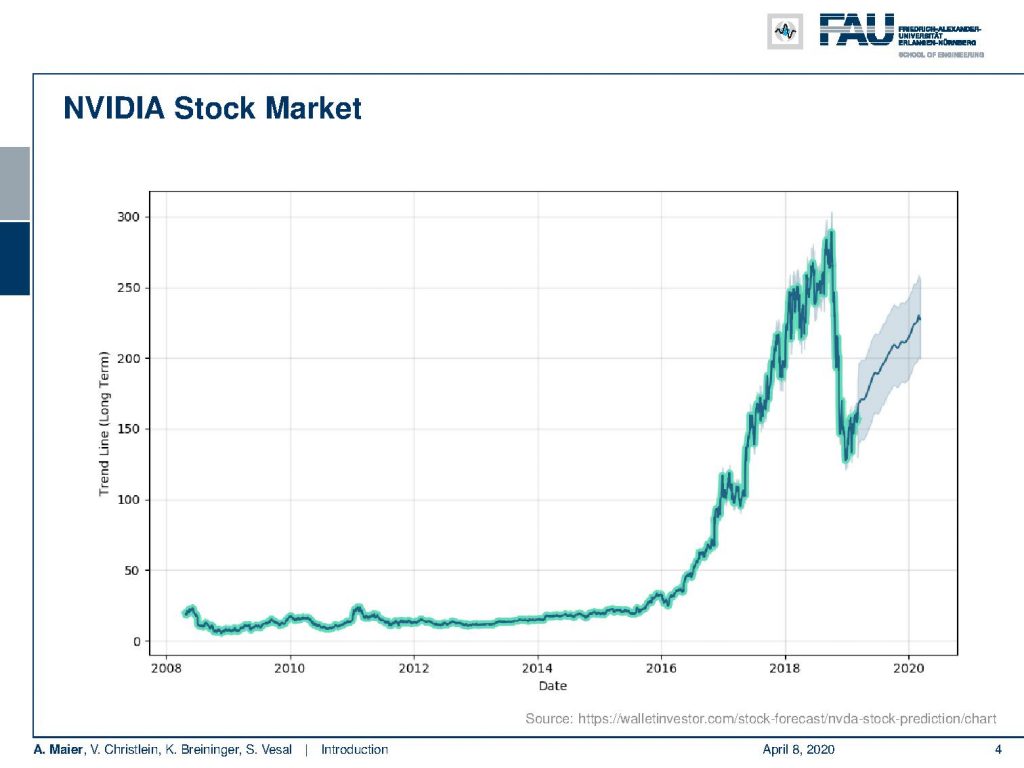
So let’s look into the motivation and what are the interesting things that are happening right now. First and foremost, I want to show you this little graph about the stock market value of Nvidia shares. You can see here that over the last couple of years in particular since 2016, the market value has been growing. One reason why this has been tremendously increasing is that in 2012 the deep learning discovery started and this really took off approximately in 2016. So, you can see as many people needed additional compute-hardware. Nvidia is manufacturing general purpose graphics processing units that allow arbitrary computation on their boards. In contrast to traditional hardware that doubles the computing capabilities within every two years, graphics boards double their compute power within approximately 14 to 16 months which means that they have quite an extraordinary amount of computing power. This enables us to train really deep networks and state-of-the-art machine learning approaches.
You can see that there is a considerable dip around 2019 / the end of 2018. Here, you can see that it’s not only deep learning that is driving the market share value of Nvidia. There’s also another very interesting thing happening at the same time and that is Bitcoin mining. The Bitcoin value really decreased in at this period of time and also the Nvidia stock market value went down. So it’s partially also associated to the Bitcoin, but you can see that the value is going up again because there’s a huge demand for compute power in deep learning.
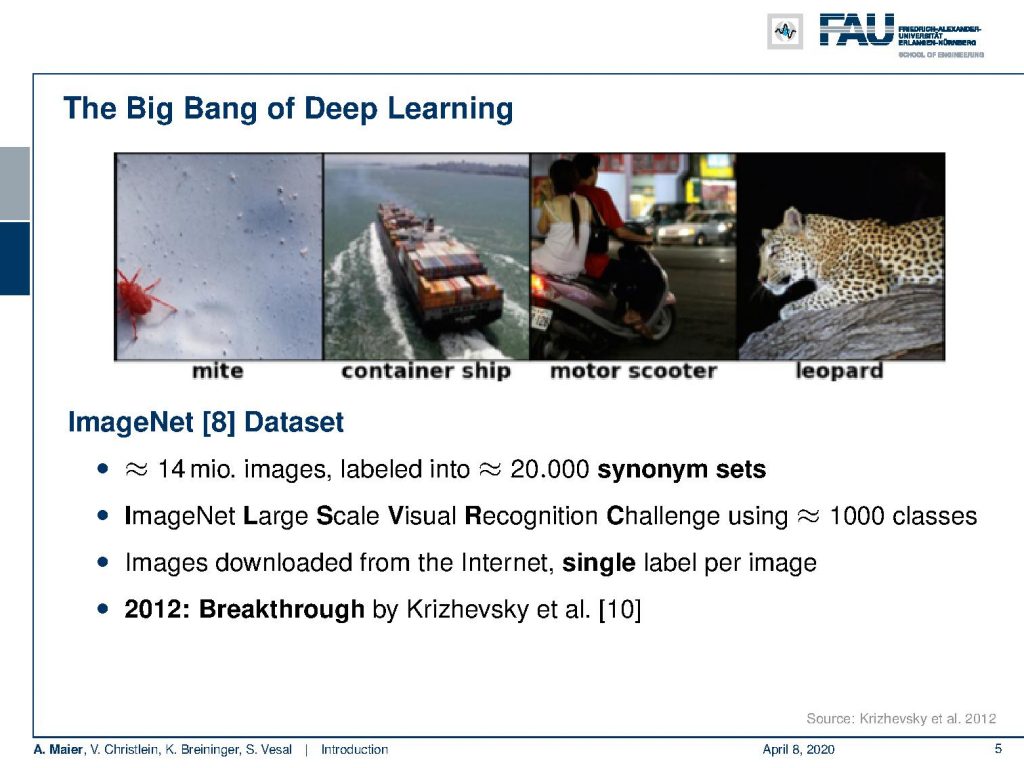
Now, what are the interesting applications that we can aim at? So, the big bang of deep learning came with the so-called image net challenge. This is a really huge data set and this huge data set has approximately 14 million images labeled into approximately 20,000 synonym sets. So. this image net large-scale visual recognition challenge is using approximately a thousand classes. Before the image net challenge, classifying into a thousand classes was essentially deemed completely impossible. The images that are used here have been downloaded from the internet and they have a single label per image. So, this is a really huge database that allows us to assign categories large numbers of categories into individual images.

Now in 2012, there was a big step ahead with the win of the Alex Network. AlexNet really halved the error rate. So, if we look at the different error rates that we have obtained over the scope of the image net challenge, you can see that we started off with error rates about 25% regarding the Top-5 error. So in 2011 and the years before, we were approximately in the ballpark of 25 percent and you could see this stalling over the last couple of years. Well in 2012, the first convolutional neural network (CNN) here was introduced and the CNN almost halved the error rate. Now that was quite a big surprise because nobody else could do it at the time. You can see that not only in 2012 there has been progressing, but in 2013 and so on the error rates more and more decreased until we essentially reached a level where they are approximately in the same range as humans.
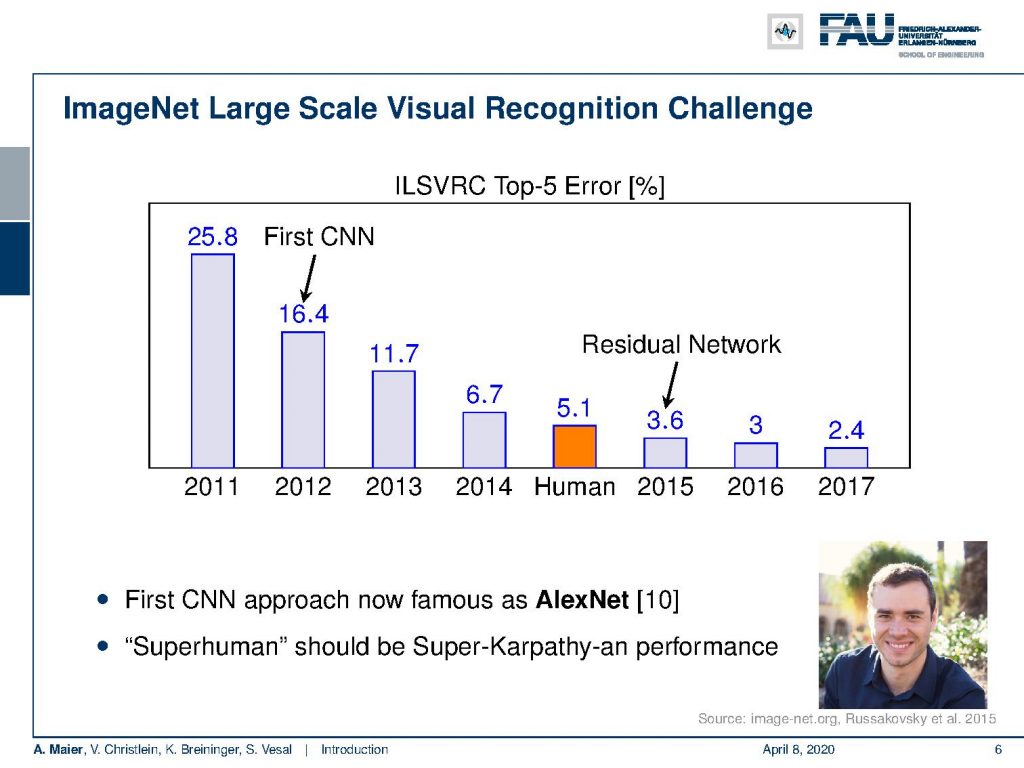
So the neural networks there reported the first results where people have been claiming that there has been superhuman performance. So, is it really superhuman performance? Well, not so many humans have really evaluated the entire test set. So, you could actually say that superhuman performance should be a super Karpathy-an performance because he actually went through the entire test dataset.

Now it’s there a problem? Well yes, there are a couple of problems with ImageNet. Well, the above the top row are probably rather easy cases, but if you look at the bottom row, there’s a couple of really difficult ones as well. So, where you have only parts of the image shown or in particular if you look at the cherry that also shows a dog, it’s very hard to differentiate those images. And of course, this is a problem if you only have a single label per image. maybe a single label is just not enough to describe an entire image.

All of these things are being used in the industry right now. There’s a huge number of deploying users ranging from Google, Apple, IBM, Deep Mind, but also many other companies are starting here. So you can see the Netflix challenge has been solved partially with deep learning. This was a 1 million dollar challenge to actually build a recommendation system that will recommend movies that you actually like. And you can see that healthcare is going in there: Siemens and GE. But also car manufacturers such as Daimler and many other carmakers are going there because there’s a huge trend towards autonomous driving.

So let’s look at a couple of really nice breakthroughs. So for example, people have been trying to beat humans in various games and we already know since 1997 that we can beat humans in chess. So in 1997 IBM’ s Deep Blue was able to beat Garry Kasparov who was a world champion in chess. But solving chess is a little easier because it has not so complex moves. The way how they actually solve the game is that they had a dictionary of starting moves. Then, they essentially did a brute-force search over the entire game in the mid part of the game and towards the end of the game again they were using a dictionary.
Now Go is a much harder challenge because in every move of the game you can place a stone on every part of the board. This means that if you really want to do an exhaustive search and look for all the different opportunities that you have in the game, only after a couple of moves the actual number of moves is exploding due to the large branching factor. At the present compute-power, we’re not able to brute-force the entire game. However, in 2016 AlphaGo, a system created by a Deep Mind really beat a professional Go player. In 2017, AlphaGo Zero even surpassed every human and only by self-playing. Then shortly later, AlphaGo Zero generalizes to a number of other board games. They even managed to go towards even other games that are not like the typical board games. In AlphaStar, they beat professional Starcraft players. So, it’s really a very interesting technology to look at.

In Google’s deep dream, there was an attempt to understand the inner workings of the network and they were interested in what the network dreams about when they present images. So the idea was to show some arbitrary input images or noise as input and then instead of adjusting the network parameters, they tweaked the input towards high activations of the network. This creates depending on we’re looking at very interesting images. So, you can create very impressive mystic images as shown here on the right-hand side with this input and the improvement by the network.

Or you can even put in the blue sky and then tweak towards neurons. Then you can see that there are all kinds of things suddenly emerging in the sky and if you look very closely you can see that there are animals showing up like the Admiral-Dog, the Pig-Snail, the Camel-Bird, or the Dog-fish.

So, what else is interesting? Well, there’s also real-time object detection that became possible with approaches like Yolo (you-look-only-once). They use multiple areas and detect bounding boxes and classify them very very quickly and this runs in real-time. It’s not just working on individual scenes images like image net, where you only have essentially one object per image but it works on completely cluttered scenes. You can even see that these detectors work on unseen input like movie scenes. Now, you may say these are very interesting examples, but can we use this everyday or is it just research that produces fancy videos?
It really works well. You may have seen that speech recognition interfaces have been improved tremendously. Also, with deep learning techniques, Siri speech recognition is now in the range where it recognizes approximately 99.7% of all the spoken words. So in a hundred words, there’s less than one word that is being miss-recognized and you can see Siri is being used. Many people use it on their phones. They use it to dictate and it even works in various environments. Also, in environments on the road when you’re outside of your house, when there’s background noises and Siri still works.
There’s also very interesting stuff that is being deployed right now by Amazon. You can see that there is this Amazon product that many people now have in their homes where they can remotely control different things. They can order and typically it works very well. But of course, users that have a rather strong accent still experience trouble.
I guess many of you also have been using Google Translate which is a very nice translation tool that has been improved quite a bit over the past two years. Maybe two years ago, they really improved in performance and this is because they switched to a general deep learning approach where they are not only learning on individual pairs of languages but they use all languages at the same time for training deep translation software. If you look into Google Translate today, a lot of the things can be translated automatically and typically it only requires a few changes in the output such that you have a very good translation. So, these are exciting high profile applications that we have seen with deep learning today.

So, next time on deep I want to show you a couple of things that have been happening not just at Google and the very big players. Actually also here in the small town of Erlangen, we have some exciting developments that I think are worth showing. So, I hope you like this video and see you next time on deep learning.
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep Learning Lecture. I would also appreciate a clap or a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
References
[1] David Silver, Julian Schrittwieser, Karen Simonyan, et al. “Mastering the game of go without human knowledge”. In: Nature 550.7676 (2017), p. 354.
[2] David Silver, Thomas Hubert, Julian Schrittwieser, et al. “Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm”. In: arXiv preprint arXiv:1712.01815 (2017).
[3] M. Aubreville, M. Krappmann, C. Bertram, et al. “A Guided Spatial Transformer Network for Histology Cell Differentiation”. In: ArXiv e-prints (July 2017). arXiv: 1707.08525 [cs.CV].
[4] David Bernecker, Christian Riess, Elli Angelopoulou, et al. “Continuous short-term irradiance forecasts using sky images”. In: Solar Energy 110 (2014), pp. 303–315.
[5] Patrick Ferdinand Christ, Mohamed Ezzeldin A Elshaer, Florian Ettlinger, et al. “Automatic liver and lesion segmentation in CT using cascaded fully convolutional neural networks and 3D conditional random fields”. In: International Conference on Medical Image Computing and Computer-Assisted Springer. 2016, pp. 415–423.
[6] Vincent Christlein, David Bernecker, Florian Hönig, et al. “Writer Identification Using GMM Supervectors and Exemplar-SVMs”. In: Pattern Recognition 63 (2017), pp. 258–267.
[7] Florin Cristian Ghesu, Bogdan Georgescu, Tommaso Mansi, et al. “An Artificial Agent for Anatomical Landmark Detection in Medical Images”. In: Medical Image Computing and Computer-Assisted Intervention – MICCAI 2016. Athens, 2016, pp. 229–237.
[8] Jia Deng, Wei Dong, Richard Socher, et al. “Imagenet: A large-scale hierarchical image database”. In: Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference IEEE. 2009, pp. 248–255.
[9] A. Karpathy and L. Fei-Fei. “Deep Visual-Semantic Alignments for Generating Image Descriptions”. In: ArXiv e-prints (Dec. 2014). arXiv: 1412.2306 [cs.CV].
[10] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. “ImageNet Classification with Deep Convolutional Neural Networks”. In: Advances in Neural Information Processing Systems 25. Curran Associates, Inc., 2012, pp. 1097–1105.
[11] Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, et al. “You Only Look Once: Unified, Real-Time Object Detection”. In: CoRR abs/1506.02640 (2015).
[12] J. Redmon and A. Farhadi. “YOLO9000: Better, Faster, Stronger”. In: ArXiv e-prints (Dec. 2016). arXiv: 1612.08242 [cs.CV].
[13] Joseph Redmon and Ali Farhadi. “YOLOv3: An Incremental Improvement”. In: arXiv (2018).
[14] Frank Rosenblatt. The Perceptron–a perceiving and recognizing automaton. 85-460-1. Cornell Aeronautical Laboratory, 1957.
[15] Olga Russakovsky, Jia Deng, Hao Su, et al. “ImageNet Large Scale Visual Recognition Challenge”. In: International Journal of Computer Vision 115.3 (2015), pp. 211–252.
[16] David Silver, Aja Huang, Chris J. Maddison, et al. “Mastering the game of Go with deep neural networks and tree search”. In: Nature 529.7587 (Jan. 2016), pp. 484–489.
[17] S. E. Wei, V. Ramakrishna, T. Kanade, et al. “Convolutional Pose Machines”. In: CVPR. 2016, pp. 4724–4732.
[18] Tobias Würfl, Florin C Ghesu, Vincent Christlein, et al. “Deep learning computed tomography”. In: International Conference on Medical Image Computing and Computer-Assisted Springer International Publishing. 2016, pp. 432–440.