
Learning Architectures
These are the lecture notes for FAU’s YouTube Lecture “Deep Learning“. This is a full transcript of the lecture video & matching slides. We hope, you enjoy this as much as the videos. Of course, this transcript was created with deep learning techniques largely automatically and only minor manual modifications were performed. If you spot mistakes, please let us know!

Welcome back to deep learning and today we want to talk about the final part of the architectures. In particular, we want to look into learning architectures. Part 5: Learning Architectures. Well, the idea here is that we want to have self-developing network structures and they can be optimized with respect to accuracy or floating-point operations. Of course, you could simply do that with a grid search. But typically that’s too time-consuming.
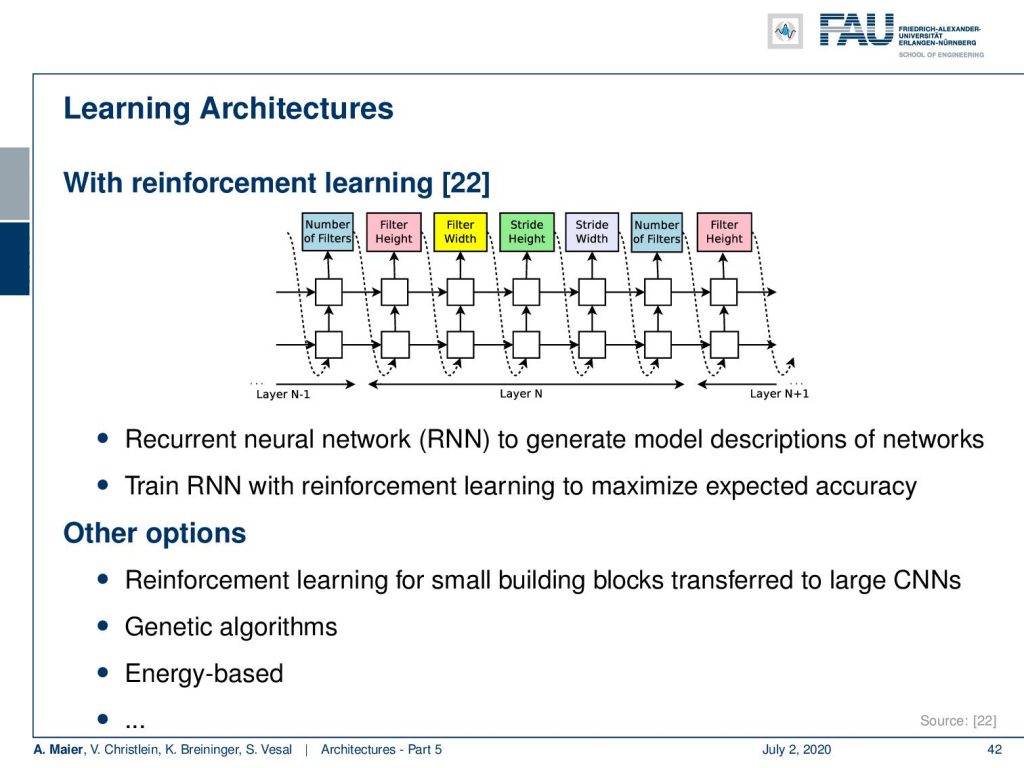
So, there have been a couple of approaches to do that. One of the ideas here in [22] is using reinforcement learning. So, you train a recurrent neural network (RNN) to generate model descriptions of networks and you train this RNN with reinforcement learning to maximize the expected accuracy. Of course, there are also many other options. You can do reinforcement learning for small building blocks transfer to large CNNs and genetic algorithms, energy-based ones, and there’s actually plenty of ideas that you could follow. They are all very expensive in terms of training time and if you want to look into those approaches, you really have to have a large cluster. Otherwise, you aren’t able to actually perform the experiments. So, there are actually not too many groups in the world that are able to do such kind of research right now.
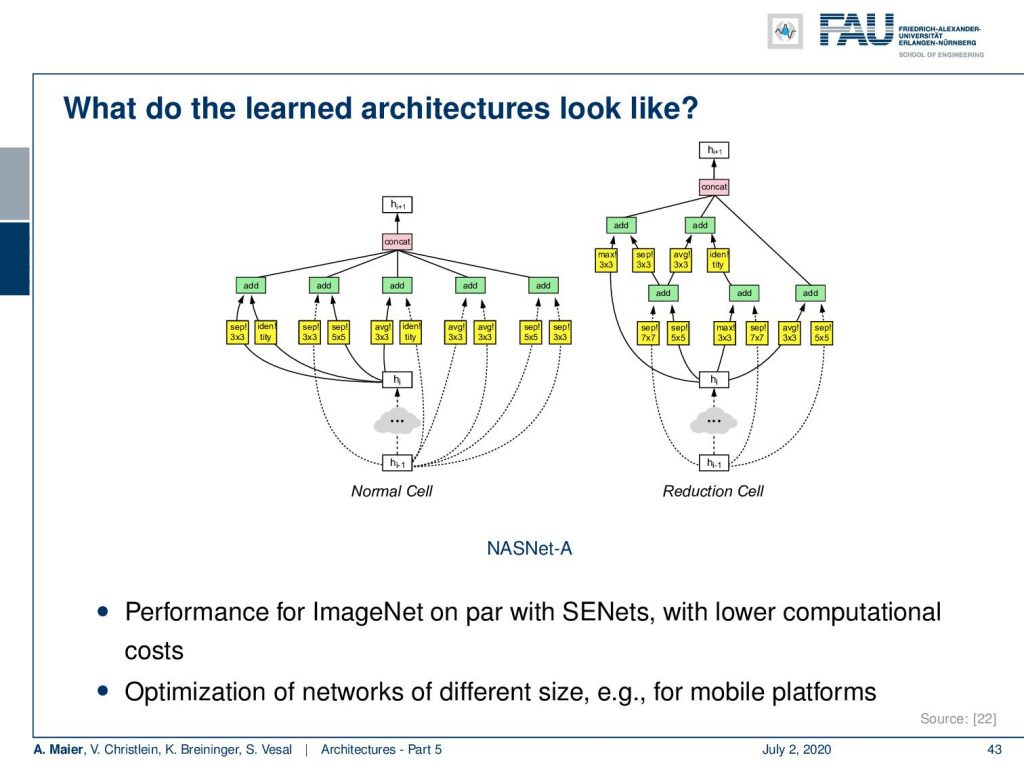
So you can see that also here many elements that we’ve seen earlier pop up again. There are separable convolutions and many other blocks here on the left-hand side. You see this normal cell kind of looks like an inception block. If you look at the right-hand side it kind of looks like later versions of the inception modules where you have these separations. They are somehow concatenated and also use residual connections. This has been determined only by architecture search. Performance for ImageNet is on par with the squeeze and excitation networks with lower computational costs. There are also, of course, optimizations possible for different sizes for example for mobile platforms.

ImageNet – Where are we? Well, we see that the ImageNet classification has dropped now below 5% in most of the submissions. Substantial and significant improvements are more and more difficult to show on this data set. The last official challenge was on CVPR in 2017. It’s now continued on Kaggle. There are new data sets that are being generated and are needed. For example, 3-D scenes, human-level understanding, and those data sets are currently being generated. there are for example things like the MS COCO dataset or the visual genome data set which have replaced ImageNet as state-of-the-art data set. Of course, there are also different research directions like speed and size of networks for mobile applications. In these situations, ImageNet may still be a suitable challenge.

So, let’s come to some conclusions. We see that the 1×1 filters reduce the parameters and add regularization. It is a very common technique. Inception modules are really nice because they allow you to find the right balance between convolution and pooling. The residual connections are a recipe that has been used over and over again. We’ve also seen that some of the new architectures can actually be learned. So, we see that there is a rise of deeper models from five layers to more than a thousand. However, often a smaller net is sufficient. Of course, this depends on the amount of training data. You can only train those really big networks if you have sufficient data. We’ve seen that sometimes it also makes sense to build wider layers instead of deep layers. You remember, we’ve already seen that in the universal approximation theorem. If we had infinitely wide layers, then maybe we could fit everything into a single layer.

Okay, that brings us already to the outlook on the next couple of videos. What we want to talk about are recurrent neural networks. We will look into long short-term memory cells, into truncated backpropagation through time which is a key element in order to be able to train those recurrent networks, and we finally have a look at the long short-term memory cell. One of the key ideas that have been driven by Schmidthuber and Hochreiter. Another idea that came up by Cho is the gated recurrent unit which can somehow be a bridge between the traditional recurrent cells and the long short-term memory cells.

Well, let’s look at some comprehensive questions: So what are the advantages of deeper models in comparison to shallow networks? Why can we say that residual networks learn an ensemble of shallow networks? You remember, I hinted on that slide this is a very important concept if you want to prepare for the exam. Of course, you should be able to describe bottleneck layers, or what is the standard inception module and how can it be improved? I have a lot of further reading dual-path networks. So you can also have a look at the squeeze and excitation networks paper. There are more interesting works that can be found here on medium and of course mobile nets and other deep networks without residual connections. This already now brings us to the end of this lecture and I hope you had fun. Looking forward to seeing you in the next video where we talk about recurrent neural networks. I heard they can be written down in five lines of code. So see you next time!
If you liked this post, you can find more essays here, more educational material on Machine Learning here, or have a look at our Deep LearningLecture. I would also appreciate a follow on YouTube, Twitter, Facebook, or LinkedIn in case you want to be informed about more essays, videos, and research in the future. This article is released under the Creative Commons 4.0 Attribution License and can be reprinted and modified if referenced.
References
[1] Klaus Greff, Rupesh K. Srivastava, and Jürgen Schmidhuber. “Highway and Residual Networks learn Unrolled Iterative Estimation”. In: International Conference on Learning Representations (ICLR). Toulon, Apr. 2017. arXiv: 1612.07771.
[2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, et al. “Deep Residual Learning for Image Recognition”. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas, June 2016, pp. 770–778. arXiv: 1512.03385.
[3] Kaiming He, Xiangyu Zhang, Shaoqing Ren, et al. “Identity mappings in deep residual networks”. In: Computer Vision – ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 2016, pp. 630–645. arXiv: 1603.05027.
[4] J. Hu, L. Shen, and G. Sun. “Squeeze-and-Excitation Networks”. In: ArXiv e-prints (Sept. 2017). arXiv: 1709.01507 [cs.CV].
[5] Gao Huang, Yu Sun, Zhuang Liu, et al. “Deep Networks with Stochastic Depth”. In: Computer Vision – ECCV 2016, Proceedings, Part IV. Cham: Springer International Publishing, 2016, pp. 646–661.
[6] Gao Huang, Zhuang Liu, and Kilian Q. Weinberger. “Densely Connected Convolutional Networks”. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, July 2017. arXiv: 1608.06993.
[7] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. “ImageNet Classification with Deep Convolutional Neural Networks”. In: Advances In Neural Information Processing Systems 25. Curran Associates, Inc., 2012, pp. 1097–1105. arXiv: 1102.0183.
[8] Yann A LeCun, Léon Bottou, Genevieve B Orr, et al. “Efficient BackProp”. In: Neural Networks: Tricks of the Trade: Second Edition. Vol. 75. Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 9–48.
[9] Y LeCun, L Bottou, Y Bengio, et al. “Gradient-based Learning Applied to Document Recognition”. In: Proceedings of the IEEE 86.11 (Nov. 1998), pp. 2278–2324. arXiv: 1102.0183.
[10] Min Lin, Qiang Chen, and Shuicheng Yan. “Network in network”. In: International Conference on Learning Representations. Banff, Canada, Apr. 2014. arXiv: 1102.0183.
[11] Olga Russakovsky, Jia Deng, Hao Su, et al. “ImageNet Large Scale Visual Recognition Challenge”. In: International Journal of Computer Vision 115.3 (Dec. 2015), pp. 211–252.
[12] Karen Simonyan and Andrew Zisserman. “Very Deep Convolutional Networks for Large-Scale Image Recognition”. In: International Conference on Learning Representations (ICLR). San Diego, May 2015. arXiv: 1409.1556.
[13] Rupesh Kumar Srivastava, Klaus Greff, Urgen Schmidhuber, et al. “Training Very Deep Networks”. In: Advances in Neural Information Processing Systems 28. Curran Associates, Inc., 2015, pp. 2377–2385. arXiv: 1507.06228.
[14] C. Szegedy, Wei Liu, Yangqing Jia, et al. “Going deeper with convolutions”. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 2015, pp. 1–9.
[15] C. Szegedy, V. Vanhoucke, S. Ioffe, et al. “Rethinking the Inception Architecture for Computer Vision”. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). June 2016, pp. 2818–2826.
[16] Christian Szegedy, Sergey Ioffe, and Vincent Vanhoucke. “Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning”. In: Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17) Inception-v4, San Francisco, Feb. 2017. arXiv: 1602.07261.
[17] Andreas Veit, Michael J Wilber, and Serge Belongie. “Residual Networks Behave Like Ensembles of Relatively Shallow Networks”. In: Advances in Neural Information Processing Systems 29. Curran Associates, Inc., 2016, pp. 550–558. A.
[18] Di Xie, Jiang Xiong, and Shiliang Pu. “All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation”. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, July 2017. arXiv: 1703.01827.
[19] Lingxi Xie and Alan Yuille. Genetic CNN. Tech. rep. 2017. arXiv: 1703.01513.
[20] Sergey Zagoruyko and Nikos Komodakis. “Wide Residual Networks”. In: Proceedings of the British Machine Vision Conference (BMVC). BMVA Press, Sept. 2016, pp. 87.1–87.12.
[21] K Zhang, M Sun, X Han, et al. “Residual Networks of Residual Networks: Multilevel Residual Networks”. In: IEEE Transactions on Circuits and Systems for Video Technology PP.99 (2017), p. 1.
[22] Barret Zoph, Vijay Vasudevan, Jonathon Shlens, et al. Learning Transferable Architectures for Scalable