This competition investigates the performance of Optical Character Recognition (OCR) systems for early-modern prints, with a main focus on font group diversity. Participants have to submit both OCR results, and font group recognition at character level. The data, which has been provided by multiple institutions, has been carefully transcribed and proof-checked by experts, and font group information has been labeled at the character level.

Notification: 28th of March
The CodaLab pages for submitting results to the two tracks are available – see Section “Submission”.
Tasks
The two following tasks will be evaluated separately:
- OCR, with Character Error Rate (CER) and Word Error Rate (WER) as metrics
- Font group recognition, with CER as metric
Tracks
The quality of OCR results depend both on methods and training data. A fair comparison of methods only requires to use the same training data, however a fair comparison of what different research groups manage to achieve requires to avoid any restriction. For this reason, this competition has the following two tracks:
- Provided data only: the networks have to be trained from scratch using only the competition’s training data. Any data augmentation technique is of course allowed (and recommended).
- Data alchemist: there is no restriction on which data is used for training the networks (other than the test data, once available, cannot be involved in any way in the training process). Using pre-trained models is allowed.
Participants are of course encouraged to submit to both tracks if possible.
Timeline
- Ongoing: participants have access to the training data
- March 15th: participants receive the test set
- April 3rd: participants submit their results, and a short description of their methodology
Data
Training and validation data, available through the links below, are split book-wise. Participants are free to merge or re-split this data as they wish, including for the first track.
https://faubox.rrze.uni-erlangen.de/getlink/fiSDupUxNJWYgBkHtwDjZx/icdar2024-comp-ocr-font.zip
The test set images are available at the following address:
https://faubox.rrze.uni-erlangen.de/getlink/fiMcQofQbJ6cmJdx2yvu5B/public-test-set.zip
Data format:
- One jpg image per text line,
- One .txt file containing the transcription per text line,
- One .font file containing font groups at character level per text line, encoded as ASCII text
Font groups are encoded as follows:
- a: Antiqua
- b: Bastarda
- f: Fraktur
- G: Gotico-Antiqua
- i: Italic
- r: Rotunda
- s: Schwabacher
- t: Textura
Font groups
In the same sequence as the list above.

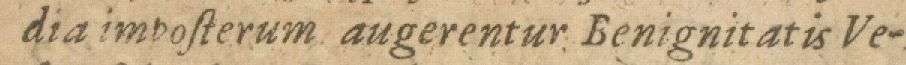


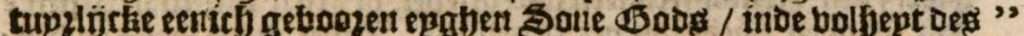
Splitting Strings
Text encoding of some of the characters used in our data requires multiple bytes. Using string iterators in Python, for example, does not deal with them properly; here is a Python code which splits a string character-wise and not byte-wise:
import re
wtf_pattern = re.compile(r'(.[\u02F3\u1D53\u0300\u2013\u032E\u208D\u203F\u0311\u0323\u035E\u031C\u02FC\u030C\u02F9\u0328\u032D\u02F4\u032F\u0330\u035C\u0302\u0327\u0357\u0308\u0351\u0304\u02F2\u0352\u0355\u032C\u030B\u0339\u0301\u02F1\u0303\u0306\u030A\u0325\u0307\u0354\u02F0\u0060\u030d\u0364\u0303]*)', re.UNICODE | re.IGNORECASE)
def split(s):
"""
Split a string using the wtf_pattern
:param s: string
:return: an array
"""
return list(wtf_pattern.findall(s))Using this method for splitting strings ensures that you will get as many characters as there are font group labels for the text lines.
Baseline Method
We will soon provide a link to a cleaned up version of the OCR model presented in “Combining OCR Models for Reading Early Modern Books” at ICDAR 2023.
Submission
We set up two CodaLab pages for submission:
Track “provided data only”: https://codalab.lisn.upsaclay.fr/competitions/18385
Track “Data alchemist”: https://codalab.lisn.upsaclay.fr/competitions/18386
If you use any external data or pre-trained model, please submit to the “data alchemist” track. If you trained models from scratch, using only the data linked above in this page, then you can submit to “provided data only”.
What to submit
The test data consists of images named “0000.jpg”, “0001.jpg”, … Your submission must consist of a .zip file containing files with the same name but different extensions:
- .txt for OCR results
- .font for character-level font classification
Following the example names above: “0000.txt”, “0000.font”, “0001.txt”, “0001.font”, …
You can place your data in subfolders as you like. If a file is missing, then the corresponding line will be considered as fully wrong (i.e., as having an edit distance equal to the length of the ground truth).
Organizers
Mathias Seuret¹
Janne van der Loop²
Dalia Rodríguez-Salas¹
Martin Mayr¹
Fei Wu¹
Florian Kordon¹
Nikolaus Weichselbaumer²
Vincent Christlein¹
¹: Pattern Recognition Lab, Friedrich-Alexander-Universität Erlangen-Nürnberg
²: Buchwissenschaft, Johannes Gutenberg Universität Mainz